I delve into a diverse range of topics, spanning programming languages, machine learning, data engineering tools, and DevOps. Our articles are enriched with practical code examples, ensuring their applicability in real-world scenarios.

Showing posts with label BERT. Show all posts
Showing posts with label BERT. Show all posts
Tuesday, February 11, 2025

Sunday, August 20, 2023
Automate Medical Coding Using BERT
Target audience: Beginner
Estimated reading time: 5'
Estimated reading time: 5'
Transformers and self-attention models are increasingly taking center stage in the NLP toolkit of data scientists [ref 1]. This article delves into the design, deployment, and assessment of a specialized transformer tasked with extracting medical codes from Electronic Health Records (EHR) [ref 2]. The focus is on curbing development and training expenses while ensuring the model remains current.

Extracting medical codes

Medical coding is the transformation of healthcare diagnosis, procedures, medical services described in electronic health records, physician's notes or laboratory results into alphanumeric codes. This study focuses on automated generation of medical codes and health insurance claims from a given clinical note or electronic health record.





fig. 6 Simplified data pipeline for active learning.
Important notes:
- This piece doesn't serve as a primer or detailed account of transformer-based encoders, Bidirectional Encoder Representations from Transformers (BERT), multi-label classification or active learning. Detailed and technical information on these models is available in the References section. [ref 1, 3, 8, 12].
- The terms medical document, medical note and clinical notes are used interchangeably
- Some functionalities discussed here are protected intellectual property, hence the omission of source code.
Introduction
Autonomous medical coding refers to the use of artificial intelligence (AI) and machine learning (ML) technologies to automatically assign medical codes to patient records [ref 4]. Medical coding is the process of assigning standardized codes to diagnoses, medical procedures, and services provided during a patient's visit to a healthcare facility. These codes are used for billing, reimbursement, and research purposes.
By automating the medical coding process, healthcare organizations can improve efficiency, accuracy, and consistency, while also reducing costs associated with manual coding.
A health insurance claim is an indication of the service given by a provider, even though the medical records associated with this service can greatly vary in content and structure. It's crucial to precisely extract medical codes from clinical notes since outcomes, like hospitalizations, treatments, or procedures, are directly tied to these diagnostic codes. Even if there are minor variations in the codes, claims can still be valid for specific services, provided the clinical notes, patient history, diagnosis, and advised procedures align.

fig. 1 Extraction of knowledge, predictions from electronic medical records
Challenges
There are 3 issues to address:
- How to extract medical codes reliably, given that labeling of medical codes is error prone and the clinical documents are very inconsistent?
- How to minimize the cost of self- training complex deep models such as transformers while preserving an acceptable accuracy?
- How to continuously keep models up to date in production environment?
Extracting medical codes
Medical codes are derived from patient records and clinical notes to forecast procedural results, determine the length of hospital stays, or generate insurance claims. The most prevalent medical coding systems include:
- International Classification of Diseases (ICD-10) for diagnosis (with roughly 72,000 codes)
- Current Procedural Terminology (CPT) for procedures and medications (encompassing around 19,000 codes)
- Along with others like Modifiers, SNOMED, and so forth.
The vast array of medical codes poses significant challenges in extraction due to:
- The seemingly endless combinations of codes linked to a specific medical document
- Varied and inconsistent formats of patient records (in terms of terminology, structure, and length.
- Complications in gleaning context from medical information systems.
Minimizing costs
A study on deep learning models suggests that training a significant language model (LLM) results in the emission of 626,155 pounds of CO2, comparable to the total emissions from five vehicles over their lifespan.
To illustrate, GPT-3/ChatGPT underwent training on 500 billion words with a model size of 175 billion parameters. A single training session would require 355 GPU-years and bear a cost of no less than $4.6M. Efforts are currently being made to fine-tune resource utilization for the development of upcoming models [ref 5].
Keeping models up-to-date
Customer data in real-time is continuously changing, often deviating from the distribution patterns the models were originally trained on (due to concept and covariate shifts).
This challenge is particularly pronounced for transformers that need task-specific fine-tuning and might even necessitate restarting the pre-training process — both of which are resource-intensive actions.
Architecture
To tackle the challenges highlighted earlier, the proposed solution should encompass four essential AI/NLP elements:
- Tokenizer to extract tokens, segments & vocabulary from a corpus of medical documents.
- Bidirectional Encoder Representations from Transformers (BERT) to generate a representation (embedding) of the documents [ref 3].
- Neural-based classifier to predict a set of diagnostic codes or insurance claim given the embeddings.
- Active/transfer learning framework to update model through optimized selection/sampling of training data from production environment.
From a software engineering perspective, the system architecture should provide a modular integration capability with current IT infrastructures. It also requires an asynchronous messaging system with streaming capabilities, such as Kafka, and REST API endpoints to facilitate testing and seamless production deployment.

fig. 2 Architecture for integration of AI components with external medical IT systems
Tokenizer
The effectiveness of a transformer encoder's output hinges on the quality of its input: tokens and segments or sentences derived from clinical documents. Several pressing questions need addressing:
- Which vocabulary is most suitable for token extraction from these notes? Do we consider domain-specific terms, abbreviations, Tf-Idf scores, etc.?
- What's the best approach to segmenting a note into coherent units, such as sections or sentences?
- How do we incorporate or embed pertinent contextual data about the patient or provider into the encoder?
Tokens play a pivotal role in formulating a dynamic vocabulary. This vocabulary can be enriched by incorporating words or N-grams from various sources like:
- Terminology from the American Medical Association (AMA)
- Common medical terms with high TF-IDF scores
- Different senses of words
- Abbreviations
- Semantic descriptions
- Stems
- .....

fig. 3 Generation of a vocabulary using training corpus and knowledge base
Our optimal approach is based on utilizing uncased words from the American Medical Association, coupled with the top 85% of terms derived from training medical notes, ranked by their highest TF-IDF scores. It's worth noting that this method can be resource-intensive.
BERT encoder
In NLP, words and documents are represented in the form of numeric vectors allowing similar words to have similar vector representations [ref 6].
The objective is to generate embeddings for medical documents including contextual data to be feed into a deep learning classifier to extract diagnostic codes or generate a medical insurance claim [ref 7].
Context embedding
Contextual information such as patient data (age, gender,...), medical service provider, specialty, or location is categorized (or bucked for continuous values) and added to the tokens extracted from the medical note.
Segmentation
Structuring electronic health records into logical or random groups of segments/sentences presents a significant challenge. Segmentation involves dividing a medical document into segments (or sections), each with an equal number of tokens that consist of sentences and relevant contextual data.
Several methods can be employed to segment a document:
- Isolating the contextual data as a standalone segment.
- Integrating the contextual data into the document's initial segment.
- Embedding the contextual data into any arbitrarily chosen segment [Ref 6].

fig. 4 Embedding of medical note with contextual data using 2 segments
Our study show the option 2 provides the best embedding for the feed forward neural network classifier.
Interestingly, treating the entire note as a single sentence and using the AMA vocabulary leads to diminished accuracy in subsequent classification tasks.
Transformer
We employ the self-supervised Bidirectional Representation for Transformer (BERT) with the objectives to:
- Grasp the contextual significance of medical phrases.
- Create embeddings/representations that merge clinical notes with contextual data.
The model construction involves two phases:
- Pretraining on an extensive, domain-specific corpus [ref 8].
- Fine-tuning tailored for specific tasks, like classification [ref 9].
After the pretraining phase concludes, the document embedding is introduced to the classifier training. This can be sourced:
- Directly from the output of the pretrained model (document embeddings).
- During the fine-tuning process of the pretrained model. Concurrently, fine-tuning operates alongside active learning for model updates."\
fig. 5 Model weights update with features extraction vs fine tuning
It's strongly advised to utilize one of the pretrained BERT models like ClinicalBERT [ref 10] or GatorTron [ref 11], and then adapt the transformer for classification purposes. However, for this particular project, we initiated BERT's pretraining on a distinct set of clinical notes to gauge the influence of vocabulary and segmentation on prediction accuracy.
Self-attention
Here's a concise overview of the multi-head self-attention model for context:
The foundation of a transformer module is the self-attention block that processes token, position, and type embeddings prior to normalization. Multiple such modules are layered together to construct the encoder. A similar architecture is employed for the decoder.
The foundation of a transformer module is the self-attention block that processes token, position, and type embeddings prior to normalization. Multiple such modules are layered together to construct the encoder. A similar architecture is employed for the decoder.

fig. 6 Schematic for transformer encoder block
Classifier
The classifier is structured as a straightforward feed-forward neural network (fully connected), since a more intricate design might not considerably enhance prediction accuracy. In addition to the standard hyper-parameter optimization, different network configurations were assessed.
The network's structure, including the number and dimensions of hidden layers, doesn't have a significant influence on the overall predictive performance.
The network's structure, including the number and dimensions of hidden layers, doesn't have a significant influence on the overall predictive performance.
Active learning
The goal is to modify models to tackle the issue of covariate shifts observed in the distribution of real-time/production data during inference.
The dual-faceted approach involves:
- Selecting data samples with labels that deviate from the distribution initially employed during training (Active learning) [ref 12].
- Adjusting the transformer for the classification objective using these samples (Transfer learning)
A significant obstacle in predicting diagnostic codes or medical claims is the steep labeling expense. In this context, learning algorithms can proactively seek labels from domain experts. This iterative form of supervised learning is known as active learning.
Because the learning algorithm selectively picks the examples, the quantity of samples needed to grasp a concept is frequently less than that required in traditional supervised learning. In this aspect, active learning parallels optimal experimental design, a standard approach in data analysis [ref 13].

In our scenario, the active learning algorithm picks an unlabeled medical note, termed note-91, and sends it to a human coder who assigns it the diagnostic code S31.623A. Once a substantial number of notes are newly labeled, the model undergoes retraining. Subsequently, the updated model is rolled out and utilized to forecast diagnostic codes on notes in production.
Thank you for reading this article. For more information ...
References
[8] Hugging face: State Of The Art NLP Model Explained
[9] What Is Fine-Tuning and How Does It Work in Neural Networks?
[9] What Is Fine-Tuning and How Does It Work in Neural Networks?
[10] ClinicalBERT: Modeling Clinical Notes and Predicting Hospital Readmission
[11] A Large Language Model for Electronic Health Records
[12] Towards data science: Active Learning in Machine Learning
[11] A Large Language Model for Electronic Health Records
[12] Towards data science: Active Learning in Machine Learning
A formal presentation of this project is available at
Glossary
- Electronic health record (EHR): An Electronic version of a patients medical history, that is maintained by the provider over time, and may include all of the key administrative clinical data relevant to that persons care under a particular provider, including demographics, progress notes, problems, medications, vital signs, past medical history, immunizations, laboratory data and radiology reports.
- Medical document: Any medical artifact related to the health of a patient. Clinical note, X-rays, lab analysis results,...
- Clinical note: Medical document written by physicians following a visit. This is a textual description of the visit, focusing on vital signs, diagnostic, recommendation and follow-up.
- ICD (International Classification of Diseases): Diagnostic codes that serve a broad range of uses globally and provides critical knowledge on the extent, causes and consequences of human disease and death worldwide via data that is reported and coded with the ICD. Clinical terms coded with ICD are the main basis for health recording and statistics on disease in primary, secondary and tertiary care, as well as on cause of death certificates
- CPT (Current Procedural Terminology): Codes that offer health care professionals a uniform language for coding medical services and procedures to streamline reporting, increase accuracy and efficiency. CPT codes are also used for administrative management purposes such as claims processing and developing guidelines for medical care review.
---------------------------
Patrick Nicolas has over 25 years of experience in software and data engineering, architecture design and end-to-end deployment and support with extensive knowledge in machine learning.
He has been director of data engineering at Aideo Technologies since 2017 and he is the author of "Scala for Machine Learning" Packt Publishing ISBN 978-1-78712-238-3
He has been director of data engineering at Aideo Technologies since 2017 and he is the author of "Scala for Machine Learning" Packt Publishing ISBN 978-1-78712-238-3
Wednesday, November 9, 2022
Enhance Stem-Based BERT WordPiece Tokenizer
Target audience: Advanced
Estimated reading time: 4'
Estimated reading time: 4'

\
Notes:
- Environments: Java 11, Scala 2.12.11
- To enhance the readability of the algorithm implementations, we have omitted non-essential code elements like error checking, comments, exceptions, validation of class and method arguments, scoping qualifiers, and import statements.
One important challenge for any NLP task is to validate parsed words against a vocabulary (set of words or tokens). What happen is a word is not defined in the vocabulary? Is the word valid or a typo? Can it be derived from words in the current vocabulary?
The Bidirectional Encoder Representations from Transformers (BERT) uses a tokenizer that address this issue.
The Bidirectional Encoder Representations from Transformers (BERT) uses a tokenizer that address this issue.
WordPiece tokenizer
The purpose of the WordPiece tokenizer is to handle out-of-vocabulary words that have not been identified and recorded in the vocabulary. This tokenizer and any of its variant are used in transformer models such as BERT or GPT.
Here are the steps for processing a word using the WordPiece tokenizer, given a vocabulary:
1 Check whether the word is present in our vocabulary
1a If the word is present in the vocabulary, then use it as a token
1b If the word is not present in the vocabulary, then split the word
into sub-words
2 Check whether the sub-word is present in the vocabulary.
2a If the sub-word is present in the vocabulary, then use it as a token
2b If the sub-word is not present in the vocabulary, then split the
sub-word
3 Repeat from 2
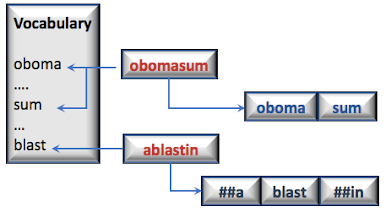
In the following example, two out of vocabulary words, obomasum and ablasting are matched against a vocabulary. The first word, obomasum is broken into two sub-words which each belong to the vocabulary. ablasting is broken into 3 sub-words for which only blast is found in the vocabulary.
Stem-based variant
Let's modify the WordPiece tokenizer to leverage stems. Stemming is the process of reducing a word to its stem. For instance the words "programmer", "programmers", "programming" and "programs" share the same stem/root, "program".

We can leverage this concept in upgrading the WordPiece tokenizer by building the original vocabulary using stems only. The vocabulary is created by parsing all words from a large corpus, extracting their stems and populate the vocabulary

Let's re-implement the WordPiece tokenizer using a pre-defined vocabulary of stems
Java implementation
The following implementation in Java can be further generalized by implementing a recursive method to extract a stem from a sub-word.
import java.util.ArrayList;
import java.util.List;
public class StemWordPieceTokenizer {
private int maxInputChars = 0;
public StemWordPieceTokenizer(int maxInputChars) {
this.maxInputChars = maxInputChars;
}
List<String> stemTokenizer(String sentence) {
List<String> outputTokens = new ArrayList<>();
String[] tokens = sentence.split("\\s+");
for(String token: tokens) {
// If the token is too long, ignore it if(token.length() > maxInputChars)
outputTokens.add("[UNK]");
// If the token belongs to the vocabulary else if(vocabulary.contains(token))
outputTokens.add(token);
else {
char[] chars = token.toCharArray();
int start = 0;
int end = 0;
while(start < chars.length-1) {
end = chars.length;
while(start < end) {
String subToken = token.substring(start, end);
// If the sub token is found in the vocabulary if(vocabulary.contains(subToken)) {
String prefix = token.substring(0, start);
// If the substring prior the token
// is also contained in the vocabulary if(vocabulary.contains(prefix))
outputTokens.add(prefix);
// Otherwise added as a word piece else if(!prefix.isEmpty()) outputTokens.add("##" + prefix); } outputTokens.add(subToken);
// Extract the substring after the token String suffix = token.substring(end);
if(!suffix.isEmpty()) { // If this substring is already in the vocabulary.. if (vocabulary.contains(suffix))
outputTokens.add(suffix);
else
outputTokens.add("##" + suffix);
}
end = chars.length;
start = end;
}
}
}
}
return outputTokens;
}
}
Scala implementation
For good measure, I include a Scala implementation.
def stemTokenize(sentence: String): List[String] = {
val outputTokens = ListBuffer[String]()
val tokens = sentence.trim.split("\\s+")
tokens.foreach(
token => {
// If the token is too long, ignore it
if (token.length > maxInputChars)
outputTokens.append("[UNK]")
// If the token belongs to the vocabulary
else if (vocabulary.contains(token))
outputTokens.append(token)
// ... otherwise attempts to break it down
else {
val chars = token.toCharArray
var start = 0
var end = 0
// Walks through the token
while (start < chars.length - 1) {
end = chars.length
while (start < end) {
// extract the stem
val subToken = token.substring(start, end)
// If the sub token is found in the vocabulary
if (vocabulary.contains(subToken)) {
val prefix = token.substring(0, start)
// If the substring prior the token
// is also contained in the vocabulary
if (vocabulary.contains(prefix))
outputTokens.append(prefix)
// Otherwise added as a word piece else if(prefix.nonEmpty)
outputTokens.append(s"##$prefix")
outputTokens.append(subToken)
// Extract the substring after the token
val suffix = token.substring(end)
if (suffix.nonEmpty) {
// If this substring is already in the vocabulary..
if (vocabulary.contains(suffix)) {
outputTokens.append(suffix)
// otherwise added as a word piece
} else if(suffix.nonEmpty)
outputTokens.append(s"##$suffix")
}
end = chars.length
start = chars.length
}
else
end -= 1
}
start += 1
}
}
}
)
outputTokens
}
Thank you for reading this article. For more information ...
Environments: JDK 11, Scala 2.12.8
---------------------------
Patrick Nicolas has over 25 years of experience in software and data engineering, architecture design and end-to-end deployment and support with extensive knowledge in machine learning.
He has been director of data engineering at Aideo Technologies since 2017 and he is the author of "Scala for Machine Learning" Packt Publishing ISBN 978-1-78712-238-3
He has been director of data engineering at Aideo Technologies since 2017 and he is the author of "Scala for Machine Learning" Packt Publishing ISBN 978-1-78712-238-3
Subscribe to:
Posts (Atom)