
Estimated reading time: 4'

- Environments: Java 11, Scala 2.12.11
- To enhance the readability of the algorithm implementations, we have omitted non-essential code elements like error checking, comments, exceptions, validation of class and method arguments, scoping qualifiers, and import statements.
The Bidirectional Encoder Representations from Transformers (BERT) uses a tokenizer that address this issue.
WordPiece tokenizer
The purpose of the WordPiece tokenizer is to handle out-of-vocabulary words that have not been identified and recorded in the vocabulary. This tokenizer and any of its variant are used in transformer models such as BERT or GPT.
Here are the steps for processing a word using the WordPiece tokenizer, given a vocabulary:
1 Check whether the word is present in our vocabulary
1a If the word is present in the vocabulary, then use it as a token
1b If the word is not present in the vocabulary, then split the word
into sub-words
2 Check whether the sub-word is present in the vocabulary.
2a If the sub-word is present in the vocabulary, then use it as a token
2b If the sub-word is not present in the vocabulary, then split the
sub-word
3 Repeat from 2
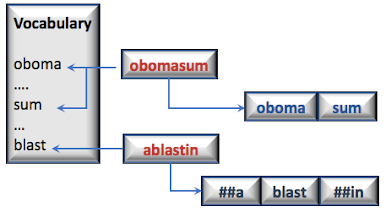
In the following example, two out of vocabulary words, obomasum and ablasting are matched against a vocabulary. The first word, obomasum is broken into two sub-words which each belong to the vocabulary. ablasting is broken into 3 sub-words for which only blast is found in the vocabulary.
Stem-based variant


Let's re-implement the WordPiece tokenizer using a pre-defined vocabulary of stems
Java implementation
The following implementation in Java can be further generalized by implementing a recursive method to extract a stem from a sub-word.
import java.util.ArrayList;
import java.util.List;
public class StemWordPieceTokenizer {
private int maxInputChars = 0;
public StemWordPieceTokenizer(int maxInputChars) {
this.maxInputChars = maxInputChars;
}
List<String> stemTokenizer(String sentence) {
List<String> outputTokens = new ArrayList<>();
String[] tokens = sentence.split("\\s+");
for(String token: tokens) {
// If the token is too long, ignore it if(token.length() > maxInputChars)
outputTokens.add("[UNK]");
// If the token belongs to the vocabulary else if(vocabulary.contains(token))
outputTokens.add(token);
else {
char[] chars = token.toCharArray();
int start = 0;
int end = 0;
while(start < chars.length-1) {
end = chars.length;
while(start < end) {
String subToken = token.substring(start, end);
// If the sub token is found in the vocabulary if(vocabulary.contains(subToken)) {
String prefix = token.substring(0, start);
// If the substring prior the token
// is also contained in the vocabulary if(vocabulary.contains(prefix))
outputTokens.add(prefix);
// Otherwise added as a word piece else if(!prefix.isEmpty()) outputTokens.add("##" + prefix); } outputTokens.add(subToken);
// Extract the substring after the token String suffix = token.substring(end);
if(!suffix.isEmpty()) { // If this substring is already in the vocabulary.. if (vocabulary.contains(suffix))
outputTokens.add(suffix);
else
outputTokens.add("##" + suffix);
}
end = chars.length;
start = end;
}
}
}
}
return outputTokens;
}
}
Scala implementation
For good measure, I include a Scala implementation.
def stemTokenize(sentence: String): List[String] = {
val outputTokens = ListBuffer[String]()
val tokens = sentence.trim.split("\\s+")
tokens.foreach(
token => {
// If the token is too long, ignore it
if (token.length > maxInputChars)
outputTokens.append("[UNK]")
// If the token belongs to the vocabulary
else if (vocabulary.contains(token))
outputTokens.append(token)
// ... otherwise attempts to break it down
else {
val chars = token.toCharArray
var start = 0
var end = 0
// Walks through the token
while (start < chars.length - 1) {
end = chars.length
while (start < end) {
// extract the stem
val subToken = token.substring(start, end)
// If the sub token is found in the vocabulary
if (vocabulary.contains(subToken)) {
val prefix = token.substring(0, start)
// If the substring prior the token
// is also contained in the vocabulary
if (vocabulary.contains(prefix))
outputTokens.append(prefix)
// Otherwise added as a word piece else if(prefix.nonEmpty)
outputTokens.append(s"##$prefix")
outputTokens.append(subToken)
// Extract the substring after the token
val suffix = token.substring(end)
if (suffix.nonEmpty) {
// If this substring is already in the vocabulary..
if (vocabulary.contains(suffix)) {
outputTokens.append(suffix)
// otherwise added as a word piece
} else if(suffix.nonEmpty)
outputTokens.append(s"##$suffix")
}
end = chars.length
start = chars.length
}
else
end -= 1
}
start += 1
}
}
}
)
outputTokens
}
Thank you for reading this article. For more information ...
He has been director of data engineering at Aideo Technologies since 2017 and he is the author of "Scala for Machine Learning" Packt Publishing ISBN 978-1-78712-238-3
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.