Estimated reading time: 5'

- This piece doesn't serve as a primer or detailed account of transformer-based encoders, Bidirectional Encoder Representations from Transformers (BERT), multi-label classification or active learning. Detailed and technical information on these models is available in the References section. [ref 1, 3, 8, 12].
- The terms medical document, medical note and clinical notes are used interchangeably
- Some functionalities discussed here are protected intellectual property, hence the omission of source code.
Introduction
Autonomous medical coding refers to the use of artificial intelligence (AI) and machine learning (ML) technologies to automatically assign medical codes to patient records [ref 4]. Medical coding is the process of assigning standardized codes to diagnoses, medical procedures, and services provided during a patient's visit to a healthcare facility. These codes are used for billing, reimbursement, and research purposes.
By automating the medical coding process, healthcare organizations can improve efficiency, accuracy, and consistency, while also reducing costs associated with manual coding.

Challenges
- How to extract medical codes reliably, given that labeling of medical codes is error prone and the clinical documents are very inconsistent?
- How to minimize the cost of self- training complex deep models such as transformers while preserving an acceptable accuracy?
- How to continuously keep models up to date in production environment?
Extracting medical codes
- International Classification of Diseases (ICD-10) for diagnosis (with roughly 72,000 codes)
- Current Procedural Terminology (CPT) for procedures and medications (encompassing around 19,000 codes)
- Along with others like Modifiers, SNOMED, and so forth.
- The seemingly endless combinations of codes linked to a specific medical document
- Varied and inconsistent formats of patient records (in terms of terminology, structure, and length.
- Complications in gleaning context from medical information systems.
Minimizing costs
Keeping models up-to-date
Architecture
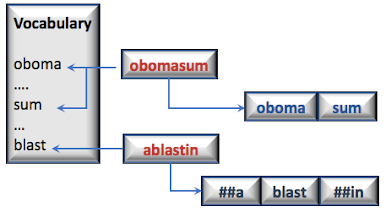
- Tokenizer to extract tokens, segments & vocabulary from a corpus of medical documents.
- Bidirectional Encoder Representations from Transformers (BERT) to generate a representation (embedding) of the documents [ref 3].
- Neural-based classifier to predict a set of diagnostic codes or insurance claim given the embeddings.
- Active/transfer learning framework to update model through optimized selection/sampling of training data from production environment.

fig. 2 Architecture for integration of AI components with external medical IT systems
Tokenizer
The effectiveness of a transformer encoder's output hinges on the quality of its input: tokens and segments or sentences derived from clinical documents. Several pressing questions need addressing:
- Which vocabulary is most suitable for token extraction from these notes? Do we consider domain-specific terms, abbreviations, Tf-Idf scores, etc.?
- What's the best approach to segmenting a note into coherent units, such as sections or sentences?
- How do we incorporate or embed pertinent contextual data about the patient or provider into the encoder?
- Terminology from the American Medical Association (AMA)
- Common medical terms with high TF-IDF scores
- Different senses of words
- Abbreviations
- Semantic descriptions
- Stems
- .....

BERT encoder
Context embedding
Segmentation
- Isolating the contextual data as a standalone segment.
- Integrating the contextual data into the document's initial segment.
- Embedding the contextual data into any arbitrarily chosen segment [Ref 6].

Transformer
- Grasp the contextual significance of medical phrases.
- Create embeddings/representations that merge clinical notes with contextual data.
- Pretraining on an extensive, domain-specific corpus [ref 8].
- Fine-tuning tailored for specific tasks, like classification [ref 9].
- Directly from the output of the pretrained model (document embeddings).
- During the fine-tuning process of the pretrained model. Concurrently, fine-tuning operates alongside active learning for model updates."\
Self-attention
The foundation of a transformer module is the self-attention block that processes token, position, and type embeddings prior to normalization. Multiple such modules are layered together to construct the encoder. A similar architecture is employed for the decoder.

Classifier
The network's structure, including the number and dimensions of hidden layers, doesn't have a significant influence on the overall predictive performance.
Active learning
- Selecting data samples with labels that deviate from the distribution initially employed during training (Active learning) [ref 12].
- Adjusting the transformer for the classification objective using these samples (Transfer learning)

References
[9] What Is Fine-Tuning and How Does It Work in Neural Networks?
[11] A Large Language Model for Electronic Health Records
[12] Towards data science: Active Learning in Machine Learning
Glossary
- Electronic health record (EHR): An Electronic version of a patients medical history, that is maintained by the provider over time, and may include all of the key administrative clinical data relevant to that persons care under a particular provider, including demographics, progress notes, problems, medications, vital signs, past medical history, immunizations, laboratory data and radiology reports.
- Medical document: Any medical artifact related to the health of a patient. Clinical note, X-rays, lab analysis results,...
- Clinical note: Medical document written by physicians following a visit. This is a textual description of the visit, focusing on vital signs, diagnostic, recommendation and follow-up.
- ICD (International Classification of Diseases): Diagnostic codes that serve a broad range of uses globally and provides critical knowledge on the extent, causes and consequences of human disease and death worldwide via data that is reported and coded with the ICD. Clinical terms coded with ICD are the main basis for health recording and statistics on disease in primary, secondary and tertiary care, as well as on cause of death certificates
- CPT (Current Procedural Terminology): Codes that offer health care professionals a uniform language for coding medical services and procedures to streamline reporting, increase accuracy and efficiency. CPT codes are also used for administrative management purposes such as claims processing and developing guidelines for medical care review.
He has been director of data engineering at Aideo Technologies since 2017 and he is the author of "Scala for Machine Learning" Packt Publishing ISBN 978-1-78712-238-3