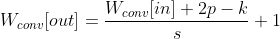Representation independence
Manifolds and Latent space
Graph Neural Networks
This article does not deal with the mathematical formalism of differential geometry or its implementation in Python.
Challenges
Deep learning
- High dimensionality: Models related to computer vision or images deal with high-dimensional data, such as images or videos, which can make training more difficult due to the curse of dimensionality.
- Availability of quality data: The quality and quantity of training data significantly affect the model's ability to generate realistic samples. Insufficient or biased data can lead to overfitting or poor generalization.
- Underfitting or overfitting: Balancing the model's ability to generalize well while avoiding overfitting to the training data is a critical challenge. Models that overfit may generate high-quality outputs that are too similar to the training data, lacking novelty.
- Embedding physics law or geometric constraints: Incorporating domain constraints such as boundary conditions or differential equations model s very challenging for high-dimensional data.
- Representation dependence: The performance of many learning algorithms is very sensitive to the choice of representation (i.e. z-normalization impact on predictors).
Generative modeling
- Performance evaluation: Unlike supervised learning models, assessing the performance of generative models is not straightforward. Traditional metrics like accuracy do not apply, leading to the development of alternative metrics such as the Frechet Inception Distance (FID) or Inception Score, which have their limitations.
- Latent space interpretability: Understanding and interpreting the latent space of generative models, where the model learns a compressed representation of the data, can be challenging but is crucial for controlling and improving the generation process.
What is differential geometry
Differential geometry is crucial in understanding the shapes and structures of objects that can be continuously altered, and it has applications in many fields including physics (I.e., general relativity and quantum mechanics), engineering, computer science, and data exploration and analysis.
Moreover, it is important to differentiate between differential topology and differential geometry, as both disciplines examine the characteristics of differentiable (or smooth) manifolds but aim for different goals. Differential topology is concerned with the overarching structure or global aspects of a manifold, whereas differential geometry investigates the manifold's local and differential attributes, including aspects like connection and metric [ref 2].
Applicability of differential geometry
Why differential geometry?
Understanding data manifolds: Data in high-dimensional spaces often lie on lower-dimensional manifolds. Differential geometry provides tools to understand the shape and structure of these manifolds, enabling generative models to learn more efficient and accurate representations of data.
Improving latent space interpolation: In generative models, navigating the latent space smoothly is crucial for generating realistic samples. Differential geometry offers methods to interpolate more effectively within these spaces, ensuring smoother transitions and better quality of generated samples.
Optimization on manifolds: The optimization processes used in training generative models can be enhanced by applying differential geometric concepts. This includes optimizing parameters directly on the manifold structure of the data or model, potentially leading to faster convergence and better local minima.
Geometric regularization: Incorporating geometric priors or constraints based on differential geometry can help in regularizing the model, guiding the learning process towards more realistic or physically plausible solutions, and avoiding overfitting.
Advanced sampling techniques: Differential geometry provides sophisticated techniques for sampling from complex distributions (important for both training and generating new data points), improving upon traditional methods by considering the underlying geometric properties of the data space.
Enhanced model interpretability: By leveraging the geometric structure of the data and model, differential geometry can offer new insights into how generative models work and how their outputs relate to the input data, potentially improving interpretability.
Physics-Informed Neural Networks: Projecting physics law and boundary conditions such as set of partial differential equations on a surface manifold improves the optimization of deep learning models.
Innovative architectures: Insights from differential geometry can lead to the development of novel neural network architectures that are inherently more suited to capturing the complexities of data manifolds, leading to more powerful and efficient generative models.
Representation independence
Manifold and latent space
- Estimate kernel density
- Approximate the encoder function of an auto-encoder
- Represent the vector space defined by classes/labels in a classifier

- By analyzing data directly on its residing manifold, you can simplify the system by reducing its degrees of freedom. This simplification not only makes calculations easier but also results in findings that are more straightforward to understand and interpret.
- Understanding the specific manifold to which a dataset belongs enhances your comprehension of how the data evolves over time.
- Being aware of the manifold on which a dataset exists enhances your ability to predict future data points. This knowledge allows for more effective signal extraction from datasets that are either noisy or contain limited data points.
Graph Neural Networks
Physics-Informed Neural Networks
Information geometry
Python libraries for differential geometry
- LaPy: Specializes in the estimation of Laplace and Heat equations, as well as the computation of differential operators like gradients and divergence. More information can be found at https://helmholtz.software/software/lapy
- diffgeom: A PyPi project aimed at symbolic differential geometry. Detailed information is available at https://pypi.org/project/diffgeom/#description
- SymPy: A more comprehensive library for symbolic mathematics, useful for studying topology and differential geometry. Documentation is accessible at https://docs.sympy.org/latest/modules/diffgeom.html
- Geomstats: Designed for performing computations and statistical analysis on nonlinear (Riemannian) manifolds. Visit https://geomstats.github.io/ for more details.
- DFormPy: A PyPi project focused on visualization and differential forms https://pypi.org/project/dformpy/
- PyG: PyTorch Geometric is a library built on PyTorch dedicated to geometric deep learning and graph neural networks https://pytorch-geometric.readthedocs.io/en/latest/
- PyRiemann A package based on scikit-learn provides a high-level interface for processing and classification of multivariate data through the Riemannian geometry of symmetric positive definite matrices https://pyriemann.readthedocs.io/en/latest/
- PyManOpt: A library for optimization and automatic differentiation on Riemannian manifolds https://pymanopt.org/