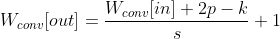Target audience: Beginner
Estimated reading time: 5'

What you will learn: How to evaluate the complexity of a 3-dimension object using fractal dimension index.
Notes:
- This article is a follow up on Fractal Dimension of Images in Python
- Environments: Python 3.11, Matplotlib 3.9.
- Source code is available at Github.com/patnicolas/Data_Exploration/fractal
- To enhance the readability of the algorithm implementations, we have omitted non-essential code elements like error checking, comments, exceptions, validation of class and method arguments, scoping qualifiers, and import statements.
Introduction
As described in a previous article, Fractal Dimension of Images in Python - Overview , a fractal dimension is a measure used to describe the complexity of fractal patterns or sets by quantifying the ratio of change in detail relative to the change in scale [ref 2].
Among the various approaches to estimate the fractal dimension, from variation, structure function methods, root mean square and R/S analysis, we selected the box counting method because of its simplicity and visualization capability.
Point cloud
To evaluate our method for calculating the fractal dimension index of an object, it's necessary to simulate or represent a 3D object. This is achieved by generating a cluster of random data points across the x, y, and z axes, commonly referred to as a point cloud.
Box counting method
The box counting method [ref 3] is described in a previous article, Box-counting method
If N is the number of measurements units for our counting boxes or cubesand eps the related scaling factor, the fractal dimension index is computed as\[ D=- \displaystyle \lim_{\epsilon \to 0} \frac{log(N)}{log(\epsilon)} \simeq - \frac{log(N)}{log(eps)} \ \ with \ N=r^3 \]We will use the height of the square box r as our measurement unit for images.
The fractal dimension index varies from 2 for very simple object to 3 for objects with complex pattern.
Implementation
Let's define a class, FractalDimObject, that encapsulates the calculation of fractal dimension and the creation of wrapping boxes.
This class provides two constructors:
- The default constructor, __init__, which accepts a 3D array xyz and a threshold value near 1.
- An alternative constructor, build, which generates a 3D array of shape (size, size, size) to simulate a 3-dimension object.
class FractalDimObject(object):
def __init__(self, xyz: np.array, threshold: float) -> None:
self.xyz = xyz
self.threshold = threshold
@classmethod
def build(cls, size: int, threshold: float) -> Self:
_xyz = np.zeros((size, size, size))
# Create a 3D fractal-like structure such as cube
for x in range(size): # Width
for y in range(size): # Depth
for z in range(size): # Height
if (x // 2 + y // 2) % 2 == 0: # Condition for non-zero values
_xyz[x, y, z] = random.gauss(size//2, size)
return cls(_xyz, threshold)The alternative constructor generates a test array for evaluation purposes. It starts by initializing the array with values of 0.0, and then assigns random Gaussian-distributed values to a specific subset of the array
The values used in define the 3D object is visualized below.

Fig. 1 Visualization of the point cloud representing 3D object
The __call__ method performs the fractal dimension calculation and tracks the relationship between box counts and sizes in three stages:
- It determines the box sizes for non-zero elements in the array.
- It counts the number of boxes for each size.
- It applies a linear regression to the logarithms of the box sizes and their corresponding counts.
def __call__(self) -> (np.array, List[int], List[int]):
# Step 1 Extract the sizes of array
sizes = self.__extract_sizes()
sizes_list = list(sizes)
sizes_list.reverse()
# Step 2 Count the number of boxes of each size
counts = [self.__count_boxes(int(size)) for size in sizes_list]
# Step 3 Fit the points to a line log(counts) = a.log(sizes) + b
coefficients = np.polyfit(np.log(sizes), np.log(counts), 1)
return -coefficients[0], sizes, countsThe __extract_sizes method is responsible for generating the box sizes, as detailed in the Appendix. The implementation of __count_boxes, which counts the wrapping boxes for a given size, follows a similar approach to the method used in calculating the fractal dimension of images.
def __count_boxes(self, box_size: int) -> int:
sx, sy, sz = self.xyz.shape
count = 0
for i in range(0, sz, box_size):
for j in range(0, sy, box_size):
for k in range(0, sz, box_size): # Wraps the non-zero values (object) with boxes
data = self.xyz[i:i+box_size, j:j+box_size, k:k+box_size]
if np.any(data): # For non-zero values (inside object)
count += 1
return count
Evaluation
Let's compute the fractal dimension of the array representing a 3D object with an initial 3D sampling grid 1024 x 1024 x 1024
import math
grid_size = 1024 # Grid size
threshold = 0.92
fractal_dim_object = FractalDimObject.build(grid_size, threshold)
coefficient, counts, sizes = fractal_dim_object()print(coefficient)
Output: 2.7456
Finally let's plot the profile of box sizes vs. box counts.

Fig. 2 Plot of box sizes vs box counts size = exp(dim*counts)
The plot reflects the linear regression of log (size) and log (counts).