
Target audience: Advanced
Estimated reading time: 5'
Estimated reading time: 5'
Working with the architecture and deployment of Generative Adversarial Networks (GANs) often involves complex details that can be difficult to understand and resolve. Consider the advantage of identifying neural components that are reusable and can be utilized in both the generator and discriminator parts of the network.

Notes:
- This post steers clear of the intricate technicalities of generative adversarial networks and convolutional neural networks. Instead, it focuses on automating the setup process for certain neural components.
- Readers are expected to have a foundational knowledge of neural networks and familiarity with the PyTorch library.
- Environments: Python 3.9, PyTorch 1.9.1
The challenge
This article is focused on streamlining the development of Deep Convolutional Generative Adversarial Networks (DCGANs) [ref 1]. We achieve this by configuring the generator in relation to the setup of the discriminator. The main area of our study is the well-known application of using GANs to differentiate between real and fake images.
Generative Adversarial Networks (GANs) [ref 2] are a type of unsupervised learning model that identify patterns within data and utilize these patterns for data augmentation, creating new samples that closely resemble the original dataset. GANs belong to the family of generative models, which also includes variational auto-encoders and maximum likelihood estimation (MLE) models. The unique aspect of GANs is that they convert the problem into a form of supervised learning by employing two competing networks:
- The Generator model, which is trained to produce new data samples.
- The Discriminator model, which aims to differentiate between real samples (from the original dataset) and fake ones (created by the Generator).
Crafting and setting up components like the generator and discriminator in a Generative Adversarial Network (GAN), or the encoder and decoder layers in a Variational Convolutional Auto-Encoder (VAE), can often be a repetitive and laborious process.
In fact, some aspects of this process can be entirely automated. For instance, the generative network in a convolutional GAN can be designed as the inverse of the discriminator using a de-convolutional network. Similarly, the decoder in a VAE can be automatically configured based on the structure of its encoder.

Functional representation of a simple deep convolutional GAN
Neural component reusability is key to generate a de-convolutional network from a convolutional network. To this purpose we break down a neural network into computational blocks.
Convolutional networks
In its most basic form, a Generative Adversarial Network (GAN) consists of two distinct neural networks: a generator and a discriminator.
Neural blocks
Each of these networks is further subdivided into neural blocks or groups of PyTorch modules, which include elements like hidden layers, batch normalization, regularization, pooling modes, and activation functions. Take, for example, a discriminator that is structured using a convolutional neural network [ref 3] followed by a fully connected (restricted Boltzmann machine) network. The PyTorch modules corresponding to each layer are organized into what we call a neural block class.
A PyTorch modules of the convolutional neural block [ref 4] are:
- Conv2d: Convolutional layer with input, output channels, kernel, stride and padding
- Dropout: Drop-out regularization layer
- BatchNorm2d: Batch normalization module
- MaxPool2d Pooling layer
- ReLu, Sigmoid, ... Activation functions

Representation of a convolutional neural block with PyTorch modules
The constructor of the neural block is designed to initialize all its parameters and modules in the correct sequence. For simplicity, we are not including regularization elements like drop-out (which essentially involves bagging of sub-networks) in this setup.
Important note: Each step of the algorithm makes reference to comments in the code (i.e. The first step [1] is to initialize the number of input and output channels refers to # [1] - initialize the input and output channels).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
3 4
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49 | class ConvNeuralBlock(nn.Module):
def __init__(self,
in_channels: int,
out_channels: int,
kernel_size: int,
stride: int,
padding: int,
batch_norm: bool,
max_pooling_kernel: int,
activation: nn.Module,
bias: bool,
is_spectral: bool = False):
super(ConvNeuralBlock, self).__init__()
# Assertions are omitted
# [1] - initialize the input and output channels
self.in_channels = in_channels
self.out_channels = out_channels
self.is_spectral = is_spectral
modules = []
# [2] - create a 2 dimension convolution layer
conv_module = nn.Conv2d(
self.in_channels,
self.out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
bias=bias)
# [6] - if this is a spectral norm block
if self.is_spectral:
conv_module = nn.utils.spectral_norm(conv_module)
modules.append(conv_module)
# [3] - Batch normalization
if batch_norm:
modules.append(nn.BatchNorm2d(self.out_channels))
# [4] - Activation function
if activation is not None:
modules.append(activation)
# [5] - Pooling module
if max_pooling_kernel > 0:
modules.append(nn.MaxPool2d(max_pooling_kernel))
self.modules = tuple(modules)
|
We considering the case of a generative model for images. The first step [#1] is to initialize the number of input and output channels, then create the 2-dimension convolution [#2], a batch normalization module [#3] an activation function [#4] and finally a max pooling module [#5]. The spectral norm regularization term [#6] is optional.
The convolutional neural network is assembled from convolutional and feedback forward neural blocks, in the following build method.
The convolutional neural network is assembled from convolutional and feedback forward neural blocks, in the following build method.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 | class ConvModel(NeuralModel):
def __init__(self,
model_id: str,
# [1] - Number of input and output unites
input_size: int,
output_size: int,
# [2] - PyTorch convolutional modules
conv_model: nn.Sequential,
dff_model_input_size: int = -1,
# [3] - PyTorch fully connected
dff_model: nn.Sequential = None):
super(ConvModel, self).__init__(model_id)
self.input_size = input_size
self.output_size = output_size
self.conv_model = conv_model
self.dff_model_input_size = dff_model_input_size
self.dff_model = dff_model
@classmethod
def build(cls,
model_id: str,
conv_neural_blocks: list,
dff_neural_blocks: list) -> NeuralModel:
# [4] - Initialize the input and output size
# for the convolutional layer
input_size = conv_neural_blocks[0].in_channels
output_size = conv_neural_blocks[len(conv_neural_blocks) - 1].out_channels
# [5] - Generate the model from the sequence
# of conv. neural blocks
conv_modules = [conv_module for conv_block in conv_neural_blocks
for conv_module in conv_block.modules]
conv_model = nn.Sequential(*conv_modules)
# [6] - If a fully connected RBM is included in the model ..
if dff_neural_blocks is not None and not is_vae:
dff_modules = [dff_module for dff_block in dff_neural_blocks
for dff_module in dff_block.modules]
dff_model_input_size = dff_neural_blocks[0].output_size
dff_model = nn.Sequential(*tuple(dff_modules))
else:
dff_model_input_size = -1
dff_model = None
return cls(
model_id,
conv_dimension,
input_size,
output_size,
conv_model,
dff_model_input_size,
dff_model)
|
The standard constructor [#1] sets up the count of input/output channels, along with the PyTorch modules for the convolutional layers [#2] and the fully connected layers [#3].
The class method, build, creates the convolutional model using convolutional neural blocks and feed-forward neural blocks. It determines the dimensions of the input and output layers based on the first and last neural blocks [#4], and then produces the PyTorch convolutional modules [#5] and modules for fully-connected layers [#6] from these neural blocks.
Following this, we proceed to construct the de-convolutional neural network utilizing the convolutional blocks.
Inverting a convolutional block
To build a GAN, one must follow these steps:
- Select and specify the PyTorch modules that will constitute each convolutional layer.
- Assemble these chosen modules into a single convolutional neural block.
- Construct the generator and discriminator of the GAN by integrating these neural blocks.
- Link the generator and discriminator to create a fully functional GAN.
The aim here is to create a builder capable of producing the de-convolutional network. This network will act as the GAN's generator, formulated on the basis of the convolutional network described in the preceding section.
The process begins with the extraction of the de-convolutional block from an already established convolutional block.

Conceptual automated generation of de-convolutional block
The standard constructor for the neural block in a de-convolutional network sets up all the essential parameters required for the network, with the exception of the pooling module (which is not necessary). The code example provided demonstrates how to create a De-convolutional neural block. This process involves using convolution parameters like the number of input and output channels, kernel size, stride, padding, along with batch normalization and the activation function.
class DeConvNeuralBlock(nn.Module):
def __init__(self,
in_channels: int,
out_channels: int,
kernel_size: int,
stride: int,
padding: int,
batch_norm: bool,
activation: nn.Module,
bias: bool) -> object:
super(DeConvNeuralBlock, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
modules = []
# Two dimension de-convolution layer
de_conv = nn.ConvTranspose2d(
self.in_channels,
self.out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
bias=bias)
# Add the deconvolution block
modules.append(de_conv)
# Add the batch normalization, if defined
if batch_norm:
modules.append(nn.BatchNorm2d(self.out_channels))
# Add activation
modules.append(activation)
self.modules = modules
|
Be aware that the de-convolution block lacks pooling capabilities. The class method named auto_build accepts a convolutional neural block, the number of input and output channels, and an optional activation function to create a de-convolutional neural block of the DeConvNeuralBlock type. The calculation of the number of input and output channels for the resulting deconvolution layer is handled by the private method __resize.
@classmethod
def auto_build(cls,
conv_block: ConvNeuralBlock,
in_channels: int,
out_channels: int = None,
activation: nn.Module = None) -> nn.Module:
# Extract the parameters of the source convolutional block
kernel_size, stride, padding, batch_norm, activation = \
DeConvNeuralBlock.__resize(conv_block, activation)
# Override the number of input_tensor channels
# for this block if defined
next_block_in_channels = in_channels
if in_channels is not None \
else conv_block.out_channels
# Override the number of output-channels for
# this block if specified
next_block_out_channels = out_channels
if out_channels is not None \
else conv_block.in_channels
return cls(
conv_block.conv_dimension,
next_block_in_channels,
next_block_out_channels,
kernel_size,
stride,
padding,
batch_norm,
activation,
False)
|
Sizing de-convolutional layers
The next task consists of computing the size of the component of the de-convolutional block from the original convolutional block.
@staticmethod
def __resize(
conv_block: ConvNeuralBlock,
updated_activation: nn.Module) -> (int, int, int, bool, nn.Module):
conv_modules = list(conv_block.modules)
# [1] - Extract the various components of the
# convolutional neural block
_, batch_norm, activation = DeConvNeuralBlock.__de_conv_modules(conv_modules)
# [2] - override the activation function for the
# output layer, if necessary
if updated_activation is not None:
activation = updated_activation
# [3]- Compute the parameters for the de-convolutional
# layer, from the conv. block
kernel_size, _ = conv_modules[0].kernel_size
stride, _ = conv_modules[0].stride
padding = conv_modules[0].padding
return kernel_size, stride, padding, batch_norm, activation
The __resize method performs several functions: it retrieves the PyTorch modules for the de-convolutional layers from the initial convolutional block [#1], incorporates the activation function into the block [#2], and ultimately sets up the parameters for the de-convolutional layer [#3].
Additionally, there's a utility method named __de_conf_modules. This method is responsible for extracting the PyTorch modules associated with the convolutional layer, the batch normalization module, and the activation function for the de-convolution, all from the convolution's PyTorch modules.
@staticmethod
def __de_conv_modules(conv_modules: list) -> \
(torch.nn.Module, torch.nn.Module, torch.nn.Module):
activation_function = None
deconv_layer = None
batch_norm_module = None
# 4- Extract the PyTorch de-convolutional modules
# from the convolutional ones
for conv_module in conv_modules:
if DeConvNeuralBlock.__is_conv(conv_module):
deconv_layer = conv_module
elif DeConvNeuralBlock.__is_batch_norm(conv_module):
batch_norm_moduled = conv_module
elif DeConvNeuralBlock.__is_activation(conv_module):
activation_function = conv_module
return deconv_layer, batch_norm_module, activation_function
Convolutional layers
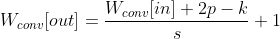
and the height of the two dimension output data is

De-convolutional layers
As expected, the formula to compute the size of the output of a de-convolutional layer is the mirror image of the formula for the output size of the convolutional layer.


Assembling de-convolutional network
Finally, a de-convolutional model, categorized as DeConvModel, is constructed using a sequence of PyTorch modules, referred to as de_conv_model. The default constructor [#1] is used once more to establish the dimensions of the input layer [#2] and the output layer [#3]. It also loads the PyTorch modules, named de_conv_modules, for all the de-convolutional layers.
class DeConvModel(NeuralModel, ConvSizeParams):
def __init__(self, # [1] - Default constructor
model_id: str,
input_size: int, # [2] - Size first layer
output_size: int, # [3] - Size output layer
de_conv_modules: torch.nn.Sequential):
super(DeConvModel, self).__init__(model_id)
self.input_size = input_size
self.output_size = output_size
self.de_conv_modules = de_conv_modules
@classmethod
def build(cls,
model_id: str,
conv_neural_blocks: list, # [4] - Input to the builder
in_channels: int,
out_channels: int = None,
last_block_activation: torch.nn.Module = None) -> NeuralModel:
de_conv_neural_blocks = []
# [5] - Need to reverse the order of convolutional neural blocks
list.reverse(conv_neural_blocks)
# [6] - Traverse the list of convolutional neural blocks
for idx in range(len(conv_neural_blocks)):
conv_neural_block = conv_neural_blocks[idx]
new_in_channels = None
activation = None
last_out_channels = None
# [7] - Update num. input channels for the first
# de-convolutional layer
if idx == 0:
new_in_channels = in_channels
# [8] - Defined, if necessary the activation
# function for the last layer
elif idx == len(conv_neural_blocks) - 1:
if last_block_activation is not None:
activation = last_block_activation
if out_channels is not None:
last_out_channels = out_channels
# [9] - Apply transposition to the convolutional block
de_conv_neural_block = DeConvNeuralBlock.auto_build(
conv_neural_block,
new_in_channels,
last_out_channels,
activation)
de_conv_neural_blocks.append(de_conv_neural_block)
# [10]- Instantiate the Deconvolutional network
# from its neural blocks
de_conv_model = DeConvModel.assemble(
model_id,
de_conv_neural_blocks)
del de_conv_neural_blocks
return de_conv_model
The alternative constructor named build is designed to generate and set up the de-convolutional model using the convolutional blocks, referred to as conv_neural_blocks [#4].
To align the order of de-convolutional layers correctly, it's necessary to reverse the sequence of convolutional blocks [#5]. For every block within the convolutional network [#6], this method adjusts the number of input channels to match the number of input channels in the first layer [#7].
It then updates the activation function for the final output layer [#8] and systematically integrates the de-convolutional blocks [#9]. Ultimately, the de-convolutional neural network is composed using these blocks [#10]..
@classmethod
def assemble(cls, model_id: str, de_conv_neural_blocks: list):
input_size = de_conv_neural_blocks[0].in_channels
output_size = de_conv_neural_blocks[len(de_conv_neural_blocks)-1].out_channels # [11]- Generate the PyTorch convolutional modules used by the default constructor
conv_modules = tuple([conv_module for conv_block in de_conv_neural_blocks
for conv_module in conv_block.modules
if conv_module is not None])
de_conv_model = torch.nn.Sequential(*conv_modules)
return cls(model_id, input_size, output_size, de_conv_model)The assemble method is responsible for building the complete de-convolutional neural network. It does this by compiling the PyTorch modules from each of the blocks in de_conv_neural_blocks into a cohesive unit [#11].
Thank you for reading this article. For more information ...
References
[2] A Gentle Introduction to Generative Adversarial Networks
[3] Deep learning Chap 9 Convolutional networks.
I. Goodfellow, Y. Bengio, A. Courville - 2017 MIT Press Cambridge MA[4] PyTorchSource code: GitHub Neural Architecture---------------------------Patrick Nicolas has over 25 years of experience in software and data engineering, architecture design and end-to-end deployment and support with extensive knowledge in machine learning.
He has been director of data engineering at Aideo Technologies since 2017 and he is the author of "Scala for Machine Learning" Packt Publishing ISBN 978-1-78712-238-3






