I delve into a diverse range of topics, spanning programming languages, machine learning, data engineering tools, and DevOps. Our articles are enriched with practical code examples, ensuring their applicability in real-world scenarios.

Tuesday, February 11, 2025

Monday, February 10, 2025
Graph Neural Network Data Loaders
Target audience: Beginner
Estimated reading time: 8'
The versatility of graph representations makes them highly valuable for solving a wide range of problems, each with its own unique data structure. However, generating universal embeddings that apply across different applications remains a significant challenge.
PyTorch Geometric (PyG) simplifies this process by encapsulating these complexities into specialized data loaders, while seamlessly integrating with PyTorch's existing deep learning modules.
PyTorch Geometric (PyG) simplifies this process by encapsulating these complexities into specialized data loaders, while seamlessly integrating with PyTorch's existing deep learning modules.

Table of Contents
What you will learn: How graph data loaders influence node classification in a Graph Neural Network implemented with PyTorch Geometric.
Notes:
- Environments: python 3.12.5, matplotlib 3.9, numpy 2.2.0, torch 2.5.1, torch-geometric 2.6.1
- Source code is available on GitHub [ref 1]
- To enhance the readability of the algorithm implementations, we have omitted non-essential code elements like error checking, comments, exceptions, validation of class and method arguments, scoping qualifiers, and import statement
Introduction
Graph Neural Networks
Data on manifolds can often be represented as a graph, where the manifold's local structure is approximated by connections between nearby points. GNNs and their variants (like Graph Convolutional Networks (GCNs)) extend neural networks to process data on non-Euclidean domains by leveraging the graph structure, which may approximate the underlying manifold [ref 2].
The list of application of graph neural networks includes
- Social Network Analysis – Modeling relationships and community detection.
- Molecular Graphs (Drug Discovery) – Predicting molecular properties.
- Recommendation Systems – Graph-based collaborative filtering.
- Knowledge Graphs – Embedding relations between entities.
- Computer Vision & NLP – Scene graphs, dependency parsing.
For more information, Graph Neural Networks are the topics of a previous article [ref 3]
PyG (PyTorch Geometric)
PyTorch Geometric (PyG) is a graph deep learning library built on PyTorch, designed for efficient processing of graph-structured data. It provides essential tools for building, training, and deploying Graph Neural Networks (GNNs) [ref 4].
The key Features of PyG are:
- Efficient Graph Processing to optimize memory and computation using sparse graph representations.
- Flexible GNN Layers that includes GCN, GAT, GraphSAGE, GIN, and other advanced architectures.
- Batching for Large Graphs to support mini-batching for handling graphs with millions of edges.
- Seamless PyTorch Integration with full compatibility with PyTorch tensors, autograd, and neural network modules.
- Diverse Graph Support for directed, undirected, weighted, and heterogeneous graphs.
The most important PyG Modules are:
- torch_geometric.data to manages graph structures, including nodes, edges, and features.
- torch_geometric.nn to provide data scientists prebuilt GNN layers like convolutional and gated layers.
- torch_geometric.transforms to pre-process input data (e.g., feature normalization, graph sampling).
- torch_geometric.loader to handle large-scale graph datasets with specialized loaders.
Important Note:
This article focuses exclusively on data loaders. Future articles will cover data processing, training, and inference of Graph Neural Networks (GNNs).
Graph Data Loaders
Overview
Some real-world applications involve handling extremely large graphs with thousands of nodes and millions of edges, posing significant challenges for both machine learning algorithms and visualization.
Fortunately, PyG (PyTorch Geometric) enables data scientists to batch nodes or edges, effectively reducing computational overhead for training and inference in graph-based models.
First we need to introduce the attributes of the data of type torch_geometric.data.Data that underline the representation of a graph in PyG.

Table 1. Attributes of graph data in PyTorch Geometric
Data Splits
The graph is divided into training, validation, and test datasets by assigning train_mask, val_mask, and test_mask attributes to the original `Data` object, as demonstrated in the following code snippet.
# 1. Define the indices for training, validation and test data points
train_idx = torch.tensor([0, 1, 2, 4, 6, 7, 8, 11, 12, 13, 14])
val_idx = torch.tensor([3, 9, 14])
test_idx = torch.tensor([5, 10])
#2. verify all indices are accounted for with no overlap
validate_split(train_idx, val_idx, test_idx)
#3. Get the training, validation and test data set
train_data = data.x[train_idx], data.y[train_idx]
val_data = data.x[val_idx], data.y[val_idx]
test_data = data.x[test_idx], data.y[test_idx]
Alternatively, we can use the RandomNodeSplit and RandomLinkSplit classes to directly extract the training, validation, and test datasets.
from torch_geometric.transforms import RandomNodeSplit
transform = RandomNodeSplit(is_undirected=True)
train_data, val_data, test_data = transform(data)
Common Loader Architectures
The graph nodes and link loaders are an extension of PyTorch ubiquitous data loader. A node loader performs a mini-batch sampling from node information and a link loader performs a similar mini-batch sampling from link information.'
The latest version of PyG supports an extensive range of graph data loaders. Below is an illustration of the most commonly used node and link loaders..
Random node loader
A data loader that randomly samples nodes from a graph and returns their induced subgraph. In this case, the two sampled subgraphs are highlighted in blue and red.
Class: RandomNodeLoader

Fig 1. Visualization of selection of graph nodes in a Random node loader
Neighbor node loader
This loader partitions nodes into batches and expands the subgraph by including neighboring nodes at each step. Each batch, representing an induced subgraph, starts with a root node and attaches a specified number of its neighbors. This approach is similar to breath-first search in trees.
class NeighborLoader

Fig 2. Visualization of selection of graph nodes in a Neighbor node loader
Neighbor link loader
This loader is similar to the neighborhood node loader. It partitions links and associated nodes into batches and expands the subgraph by including neighboring nodes at each step
Class LinkNeigbhorLoader

Fig 3. Visualization of selection of graph nodes in a Neighbor link loader
Subgraphs Cluster
Divides a graph data object into multiple subgraphs or partitions. A batch is then formed by combining a specified number (`batch_size`) of subgraphs. In this example, two subgraphs, each containing five green nodes, are grouped into a single batch.
Class ClusterData

Fig 4. Visualization of selection of graph nodes in a cluster loader
Graph Sampling Based Inductive Learning Method
This is an inductive learning approach that enhances training efficiency and accuracy by constructing mini-batches through sampling subgraphs from the training graph, rather than selecting individual nodes or edges from the entire graph. This approach is similar to depth-first search in trees.
Classes: GraphSAINTNodeSampler, GraphSAINTRandomWalkSampler
This is an inductive learning approach that enhances training efficiency and accuracy by constructing mini-batches through sampling subgraphs from the training graph, rather than selecting individual nodes or edges from the entire graph. This approach is similar to depth-first search in trees.
Classes: GraphSAINTNodeSampler, GraphSAINTRandomWalkSampler

Fig 5. Visualization of selection of graph nodes in a Graph SAINT random walk
Evaluation
Let's analyze the impact of different graph data loaders on the performance of a Graph Convolutional Neural Network (GCN).
To facilitate this evaluation, we'll create a wrapper class, `GraphDataLoader`, for managing data loading. The `__call__` method directs requests to the appropriate node or link sampler/loader, with an optional num_workers parameter for parallel processing.
The arguments of the constructor are:
- loader_attributes: Dictionary for the configuration of this specific loader
- data: The graph data of type torch_geometric.data.Data
# --- Code Snippet 1 ---
from torch_geometric.data import Data from torch.utils.data import DataLoader from torch_geometric.loader import (NeighborLoader, RandomNodeLoader,
GraphSAINTRandomWalkSampler, GraphSAINTNodeSampler, GraphSAINTEdgeSampler, ShaDowKHopSampler, ClusterData, ClusterLoader)
from networkx import Graph
class GraphDataLoader(object):
def __init__(self,
loader_attributes: Dict[AnyStr, Any],
data: Data) -> None:
self.data = data
self.attributes_map = loader_attributes
# Routing to the appropriate loader given the attributes dictionary
def __call__(self, num_workers: int) -> (DataLoader, DataLoader):
match self.attributes_map['id']:
case 'NeighborLoader':
return self.__neighbors_loader()
case 'RandomNodeLoader':
return self.__random_node_loader()
case 'GraphSAINTNodeSampler':
return self.__graph_saint_node_sampler()
case 'GraphSAINTEdgeSampler':
return self.__graph_saint_edge_sampler()
case 'ShaDowKHopSampler':
return self.__shadow_khop_sampler()
case 'GraphSAINTRandomWalkSampler':
return self.__graph_saint_random_walk(num_workers)
case 'ClusterLoader':
return self.__cluster_loader()
case _:
raise DatasetException(f'Data loader {self.attributes_map["id"]} not supported') To keep this article concise, our evaluation focuses on the following three graph data loaders:
- Random Nodes
- Neighbors Nodes
- Graph SAINT Random Walk
Random Node Loader
The only configuration attribute for the random node loader is num_parts that controls how the dataset is partitioned into smaller chunks for efficient sampling. The data set is split into num_parts subgraphs to improve performance and parallelization for large graphs. We use the default batch_size 128.
The loader for the training set shuffles the data while the order of data points for the validation set is preserved.
# --- Code Snippet 2 ---
def __random_node_loader(self) -> (DataLoader, DataLoader):
num_parts = self.attributes_map['num_parts']
train_loader = RandomNodeLoader(self.data, num_parts=num_parts, shuffle=True) val_loader = RandomNodeLoader(self.data, num_parts=num_parts, shuffle=False) return train_loader, val_loader
We consider the Flickr data set included in Torch Geometric (PyG) described in [ref 5]. As a reminder, The Flickr dataset is a graph where nodes represent images and edges signify similarities between them [ref 6]. It includes 89,250 images and 899,756 relationships. Node features consist of image descriptions and shared properties.
T. The purpose is to classify Flickr images (defined as graph nodes) into one of the 108 categories.
I # --- Code Snippet 3 ---
import os
from torch_geometric.datasets.flickr import Flickr
import torch_geometric
# Load the Flickr data set then extract the first and only graph data # from the dataset
path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', 'data', 'Flickr')
_dataset: Dataset = Flickr(path)
_data: torch_geometric.data.data.Data = _dataset[0]
# Define the appropriate attribute for this loader: Random nodes
attrs = {
'id': 'RandomNodeLoader',
'num_parts': 256
}
graph_data_loader = GraphDataLoader(loader_attributes= attrs, data=_data)
# Invoke of generic __call__
train_data_loader, test_data_loader = graph_data_loader()
We train a three-layer message-passing Graph Convolutional Neural Network (GCN) on the Flickr dataset for classify these images into 108 categories. In this first experiment the model trains on data extracted by the random node loader. For clarity, the code for training the model, computing losses, and evaluating performance metrics has been omitted.
The following plot tracks the various performance metrics (accuracy, precision and recall) as well as the training and validation loss over 60 iterations.
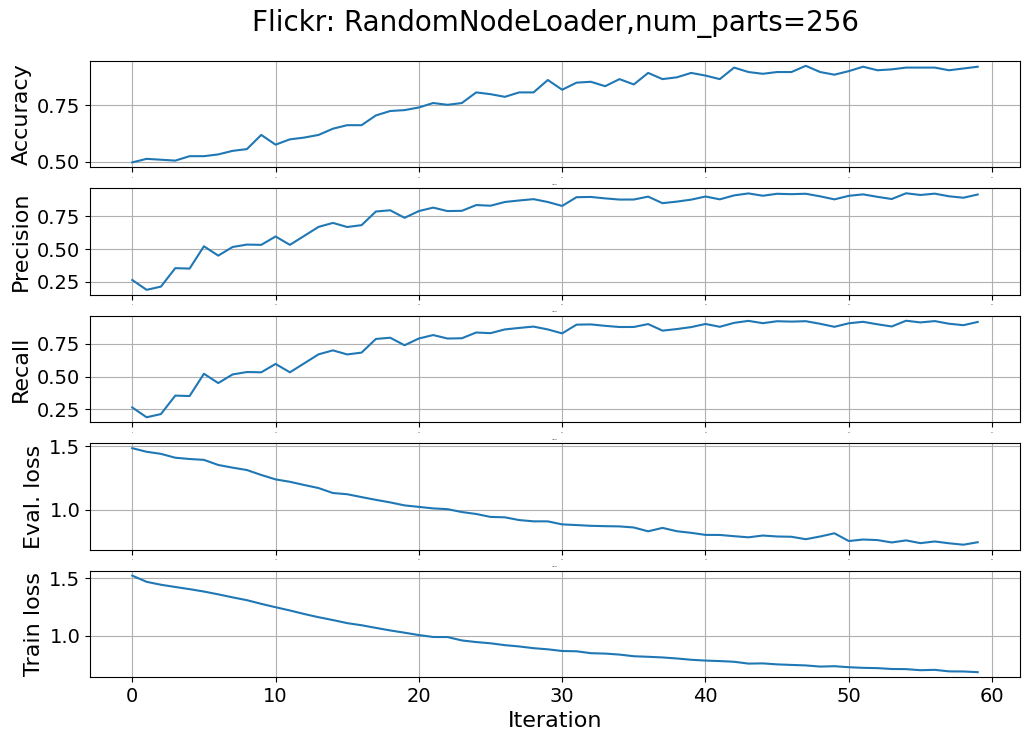
Fig 6. Performance metrics and loss for a GCN in a multi-label classification of data loaded randomly
Neighbor Node Loader
The configuration parameters used for this loader include:
- num_neighbors: Specifies the number of neighbors to sample at each layer or hop in a Graph Neural Network. It is defined as an array, e.g., `[num_neighbors_first_hop, num_neighbors_second_hop, ...]`.
- replace: Determines whether sampling is performed with or without replacement.
- batch_size; Size of the batch
We specify few other parameters which value do not vary during our evaluation>
- drop_last: to drop the last batch is it is less that the prescribed batch_size
- input_nodes for the applying the mask for training and validation data
# --- Code Snippet 4 ---
def __neighbors_loader(self) -> (DataLoader, DataLoader):
# Extract loader configuration
num_neighbors = self.attributes_map['num_neighbors']
batch_size = self.attributes_map['batch_size']
replace = self.attributes_map['replace']
# Generate the loader for training data
train_loader = NeighborLoader(self.data,
num_neighbors=num_neighbors,
batch_size=batch_size,
replace=replace,
drop_last=False,
shuffle=True,
input_nodes=self.data.train_mask)
# Generate the loader for validation data
val_loader = NeighborLoader(self.data,
num_neighbors=num_neighbors,
batch_size=batch_size,
replace=replace,
drop_last=False,
shuffle=False,
input_nodes=self.data.val_mask)
return train_loader, val_loader
We only need to update the dictionary of this loader configuration parameters in the code snippet 3.
# --- Code Snippet 5 ---
attrs = { 'id': 'NeighborLoader', 'num_neighbors': [6, 4], 'batch_size': 1024, 'replace': True }
The training and validation of the Graph Convolutional Neural Network produces the following plots for the performance metrics and losses.

Fig 7. Performance metrics and loss for a GCN in a multi-label classification of data loaded with a Neighbor loader
Graph Sampling Based Inductive Learning loader
For evaluating this loader, we use the following configuration parameters:
- walk_length: Defines the number of hops (nodes) in a single random walk
- batch_size: Size of the batch of subgraph
- num_steps: Number of times new nodes are samples in each epoch
- sample_coverage: Number of times each node is sampled: appeared in a batch.
# --- Code Snippet 6 --- def __graph_saint_random_walk(self,
num_workers: int) -> (DataLoader, DataLoader): # Dynamic configuration parameter for the loader walk_length = self.attributes_map['walk_length'] batch_size = self.attributes_map['batch_size'] num_steps = self.attributes_map['num_steps'] sample_coverage = self.attributes_map['sample_coverage'] # Extraction of the loader for training data train_loader = GraphSAINTRandomWalkSampler(data=self.data, batch_size=batch_size, walk_length=walk_length, num_steps=num_steps, sample_coverage=sample_coverage, shuffle=True) # Extraction of the loader for validation data val_loader = GraphSAINTRandomWalkSampler(data=self.data, batch_size=batch_size, walk_length=walk_length, num_steps=num_steps, sample_coverage=sample_coverage, shuffle=False) return train_loader, val_loader
Once again, we reuse the implementation in code snippet 3 and update the dictionary of this loader configuration parameters.
# --- Code Snippet 7 ---
attrs = {
'id': 'GraphSAINTRandomWalkSampler', 'walk_length': 3,
'num_steps': 12,
'sample_coverage': 100,
'batch_size': 4096
}

Fig 8. Performance metrics and loss for a GCN in a multi-label classification of data loaded with a Graph SAINT random walk loader
The performance metrics, accuracy, precision and recall points to an inability for the Random walk to capture long-range dependencies.
Comparison
Lastly, let's compare the impact of each data loader on the precision of the graph convolutional neural network..

Fig 9. Plotting precision in a multi-label classification of a GCN with various graph data loaders
Although the random walk for the GraphSAINTRandomWalk loader excels in analyzing and representing local structure, it fails to capture the global context (high number of hops - dependencies) of a large image set. Moreover, the plot highlights the high degree of instability of performance metrics even though the loss in the validation run converges appropriately.
NeighborNodeLoader select nodes across multiple hops and therefore avoid over emphasis on nodes sampled in nearby regions.
Here is a summary of benefits, drawbacks and applicability of the 3 graph data loaders.

Table 2. Pros and cons of Random node, Neighbor node and Random walk loaders
Sunday, January 19, 2025
Visualization Graph Neural Networks
Target audience: Beginner
Estimated reading time: 4'
Newsletter: Geometric Learning in Python
Have you ever found it challenging to represent a graph from a very large dataset while building a graph neural network model?
This article presents a method to sample and visualize a subgraph from such datasets.

What you will learn: How to sample and visualize a graph from a very large dataset for modeling graph neural networks.
Notes:
- Environments: python 3.12.5, matplotlib 3.9, numpy 2.2.0, torch 2.5.1, torch-geometric 2.6.1, networkx 3.4.2
- Source code is available on GitHub [ref 1]
- To enhance the readability of the algorithm implementations, we have omitted non-essential code elements like error checking, comments, exceptions, validation of class and method arguments, scoping qualifiers, and import statement.
Introduction
This article focuses on visualizing subgraphs within the context of graph neural networks. It does not cover the introduction or explanation of graph neural network architectures and models, as those topics are beyond its scope [ref 2, 3].
Note: There are several Python libraries available for analyzing and visualizing graphs, including Plotly, PyVis, and NetworkKit. In some of our future articles on graph neural networks and geometric deep learning, we will use NetworkX for visualization.
As a reminder, a graph data is fully defined by an instance of Data of torch_geometric.data package with the following property
- data.x: Node feature matrix with shape num_nodes, num_node_features
- data.edge_index: Graph connectivity with shape 2, num_edges and type torch.Long
- data.edge_attr: Edge feature matrix shape: num_edges, num_edge_features
- data.y: Target to train against (may have arbitrary shape), e.g., node-level targets of shape [num_nodes, *] or graph-level targets of shape [1, *]
- data.pos: Node position matrix with shape num_nodes, num_dimensions
NetworkX library
Overview
NetworkX is a BSD-license powerful and flexible Python library for the creation, manipulation, and analysis of complex networks and graphs. It supports various types of graphs, including undirected, directed, and multi-graphs, allowing users to model relationships and structures efficiently [ref 4]
NetworkX provides a wide range of algorithms for graph theory and network analysis, such as shortest paths, clustering, centrality measures, and more. It is designed to handle graphs with millions of nodes and edges, making it suitable for applications in social networks, biology, transportation systems, and other domains. With its intuitive API and rich visualization capabilities, NetworkX is an essential tool for researchers and developers working with network data.
The library supports many standard graph algorithms such as clustering, link analysis, minimum spanning tree, shortest path, cliques, coloring, cuts, Erdos-Renyi or graph polynomial.
Sampling large graphs
Most datasets included in the PyG library contain an extremely large number of nodes and edges, making them impractical to visualize directly. To address this, we can extract (or sample) one or more subgraphs that are easier to display.
In our design, a subgraph is derived from the original large graph by sampling its nodes and edges based on a specified range of indices, as shown below:

Fig. 1 Illustration of sampling a large graph data
In the illustration above, the sampled nodes are [12, ...., 19]
Implementation
For the sake of simplicity, let wraps the visualization of a graph neural network data into a class GNNPlotter which constructor takes 3 parameters [ref 4]:
- graph: Reference to NetworkX directed or undirected graph
- data: Data representation of the graph dataset
- samples_node_index_range: Tuple (index of first sampled node, index of last sampled node)
import networkx as nx
from networkx import Graph
from torch_geometric.data import Data
from typing import Tuple, AnyStr, Callable, Dict, Any, Self, List
import matplotlib.pyplot as plt
class GNNPlotter(object): # Default constructor
def __init__(self, graph: Graph, data: Data, sampled_node_index_range: Tuple[int, int] = None) -> None:
self.graph = graph
self.data = data
self.sampled_node_index_range = sampled_node_index_range
# Constructor for undirected graph @classmethod def build(cls, data: Data, sampled_node_index_range: Tuple[int, int] = None) -> Self: return cls(nx.Graph(), data, sampled_node_index_range)
# Constructor for directed graph@classmethod def build_directed(cls,
data: Data, sampled_node_index_range: Tuple[int, int] = None) -> Self:
return cls(nx.DiGraph(), data, sampled_node_index_range)# Sample/extract a subgraph from a large graph by selecting
# its nodes through a range of indices def sample(self) -> None:
# # Display/visualize a subgraph extracted/sampled from a large graph
# by selecting its nodes through a range of indices def draw(self, layout_func: Callable[[Graph], Dict[Any, Any]], node_color: AnyStr, node_size: int, title: AnyStr) -> None:
Simplified constructor for directed (build) and undirected graph (build_directed) are also provided.
Let’s first review our implementation for sampling graph vertices and edges, which involves the following steps:
- Transpose the list of edge indices.
- If a range for sampling indices is defined, use it to extract the indices of the first node, sampled_node_index_range[0], and the last node, last_node_index, in the subgraph.
- Add the edge indices associated with the selected nodes.
def sample(self) -> int:
# 1. Create edge indices vector
edge_index = self.data.edge_index.numpy()
transposed = edge_index.T
# 2. Sample the edges of the graph
if self.sampled_node_index_range is not None:
last_node_index = len(self.data.y) \ if self.sampled_node_index_range[1] >= len(self.data.y) \
else self.sampled_node_index_range[1]
condition = ((transposed[:, 0] >= self.sampled_node_index_range[0]) & \ (transposed[:, 0] <= last_node_index))
sampled_nodes = transposed[np.where(condition)]
else:
sampled_nodes = transposed
# 3. Assign the samples to the edge of the graph
self.graph.add_edges_from(sampled_nodes)
return len(sampled_nodes)Finally, the visualization of the graph is achieved by drawing it with the draw method and overlaying the edges using draw_networkx_edges.
In our basic application, we define the layout, customize the color and size of the nodes, and set the title for the display.
def draw(self,
layout_func: Callable[[Graph], Dict[Any, Any]],
node_color: AnyStr,
node_size: int,
title: AnyStr) -> int:
num_sampled_nodes = self.sample()
# Plot the graph using matplotlib
plt.figure(figsize=(8, 8))
# Draw nodes and edges
pos = layout_func(self.graph)
nx.draw(self.graph, pos, node_size=node_size, node_color=node_color)
nx.draw_networkx_edges(self.graph, pos, arrowsize=40, alpha=0.5, edge_color="black")
# Configure plot
plt.title(title)
plt.axis("off")
plt.show()
return num_sampled_nodes
Layouts
NetworkX provides several graph layouts to visually display undirected graphs. Each layout arranges nodes in a specific pattern, suited to different types of graphs and visualization purposes. Here's a brief overview of the common layouts available in networkx [ref 4]
- Spring Layout: Positions nodes using a force-directed algorithm. Nodes repel each other, while edges act as springs pulling connected nodes closer.
- Circular Layout: Arranges nodes uniformly on a circle.
- Shell Layout: Arranges nodes in concentric circles (shells). Useful for graphs with hierarchical structures.
- Planar Layout: Positions nodes to ensure no edges overlap, provided the graph is planar.
- Kamada-Kawai Layout: Positions nodes to minimize the "energy" of the graph. Produces aesthetically pleasing layouts similar to `spring_layout`.
- Spectral Layout: Positions nodes using the eigenvectors of the graph Laplacian. Captures graph structure in the arrangement.
- Random Layout: Places nodes randomly within a unit square.
- Spiral Layout: Positions nodes in a spiral pattern.
Graph representation
Let's consider the Flickr data set included in Torch Geometric (PyG) described in [ref 5]. As a reminder, The Flickr dataset is a graph where nodes represent images and edges signify similarities between them [ref 6]. It includes 89,250 images and 899,756 relationships. Node features consist of image descriptions and shared properties.
Let's apply the class GNNPlotter methods to the Flickr data set, selecting the edges for nodes of index starting 12 to 21 included, using the spring layout.
# Load the Flickr data
path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', 'data', 'Flickr')
# Invoke the built-in PyG data loader for Flickr data
_dataset: Dataset = Flickr(path)
_data = _dataset[0]
# Setup the sampling of the undirected graph
gnn_plotter = GNNPlotter.build(_data, sampled_node_index_range =(12, 21))
# Draw the sampled graph
num_sampled_nodes =gnn_plotter.draw( layout_func=lambda graph: nx.spring_layout(graph, k=1),
node_color='blue',
node_size=40,
title='Flickr spring layout')
print(f'Sample size: {num_sampled_nodes}')Output: 319
The 319 vertices of the Flickr graph data set and its undirected edges are visualized using the spring layout. The visualization covers 319/89,250 = 0.35% of the entire dataset of images.

Fig. 2 Display of sampled sub-graph from Flickr data set using spring layout
Examples of graph display configurations are listed in the Appendix.
Comparing layouts
Undirected graph representation
Let’s demonstrate six common layouts for displaying subgraphs sampled from the Flickr dataset using 67 nodes.

Fig. 3 Display of sampled sub-graph from Flickr data set using 6 common layouts
Finally, let’s apply the same layout to a directed graph derived from the Flickr dataset.

Fig. 4 Display of directed sub-graph from Flickr data set using 6 common layouts
Subscribe to:
Posts (Atom)