
Target audience: Beginner
Estimated reading time: 4'

Table of contents
Overview
The Scala programming language supports three different approaches to handle errors.- Error codes
- Exceptions
- Option monadic pattern
The Java and C++ programmers are familiar with the first 2 approaches. Scala introduces the Option type which is defined as a Monad.
Let's take a simple example; computation of the function sin(sqrt(x). The client code unwraps the return type, Option[Double] to handle the error.
An alternative is to use a default value with getOrElse in case or failure.
Caution: You should never insecurely unwrap an option using the method get.
sqrt(-3.0).get generates a java.util.NoSuchElementException: None.get exception.
Option type has few important benefits:
Note: For the sake of readability of the implementation of algorithms, all non-essential code such as error checking, comments, exception, validation of class and method arguments, scoping qualifiers or import is omitted
Let's take a simple example; computation of the function sin(sqrt(x). The client code unwraps the return type, Option[Double] to handle the error.
def sqrt(x: Double): Option[Double] = {
if(x < 0.0) None
else Some(Math.sqrt(x))
}
sqrt(a) match {
case Some(a) => Math.sin(a)
case None => Console.println(s"argument $a < 0.0")
}
An alternative is to use a default value with getOrElse in case or failure.
sqrt(a).map( Math.sin(_) ).getOrElse {s"argument $a < 0.0"; 0.0 }
Caution: You should never insecurely unwrap an option using the method get.
sqrt(-3.0).get generates a java.util.NoSuchElementException: None.get exception.
Option type has few important benefits:
- The return type None represents absence of returned value or reference, which is safer to process by the client code than a return Null (i.e stray pointers)
- The Option type allows developers to create their own error handler: case None => f(do whatever you want or need to do)
- The returned value(s) and error handler are encapsulate into the same entity, Option class.
Note: For the sake of readability of the implementation of algorithms, all non-essential code such as error checking, comments, exception, validation of class and method arguments, scoping qualifiers or import is omitted
Evaluation
I selected the division of double precision floating point values as our simple test. The simple test code, below is compiled and run with Scala 2.10.2 and Java JDK 1.7._45 on 64-bit Windows. 1
2
3
4
5
6
7
8
9
10
11
12
13
14 | // Handling divide by zero using error code NaN
def divErrorCode(x : Double, y : Double) : Double =
if( Math.abs(y) < 1e-10) Double.NaN else x/y
// Handling divide by zero using Arithmetic Exception
def divException(x : Double, y : Double) : Double = {
if( Math.abs(y) < 1e-10)
throw new ArithmeticException("Cannot divide by 0")
x/y
}
// Handling divide by zero using Option[Double] return type
def divOption(x : Double, y : Double) : Option[Double] =
if( Math.abs(y) < 1e-10) None else Some(x/y)
|
The source code for the three handling errors follows:
1
2
3
4
5
6
7
8
9 | // Option error handling
divOption(x,y).getOrElse(-1.0)
// Exception error handling
Try ( divException(x,y) ).getOrElse(-1.0)
// Return value error handling
val result = divErrorCode(x,y)
if( result.isNaN) -1.0 else result
|
Positive test
The test consists of running each of those local functions through a large number of iteration varying from 2,000,000 to 18,000,000. The graph that summarizes the test is defined below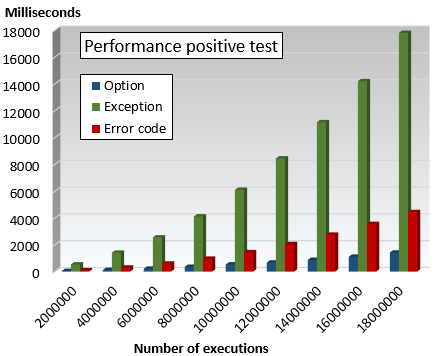
Negative test
We run the same test with the number of iterations varying from 200,000 to 1,800,000, but with an arithmetic error at each iteration.
Performance is only one of the elements to consider when selecting the most appropriate error handling mechanism. However, all things being equal, the overhead generated by repeatedly throwing exception (i.e. lengthy iteration or recursion) should be an incentive to consider alternative solutions
Note: The evaluation of the error handling mechanism has been performed using Scala 2.9. Results may vary in future releases.
References
- Option Type in Wikipedia
- Option in Scala by David Matsuzek
- Programming in Scala - M. Odersky, L.Spoon, B. Venners - Artima 2007
- github.com/patnicolas





{kind=link}
{kind=link}