
Target audience: Advanced
Estimated reading time: 6'
"Mathematics is security. Certainty. Truth. Beauty. Insight. Structure. Architecture. Whether it is differential topology, or functional analysis, or homological algebra, it is all one thing. ..." Paul Halmos

Table of contents
Notes:
- This post requires a solid knowledge of functional programming as well understanding of differential geometry.
- Implementation relies on Scala 2.12.10
Overview
Scala is a premier language that seamlessly integrates functional programming and object-oriented paradigms, supporting various advanced concepts including higher-kind types, functors, and monads. This article demonstrates Scala's ability to utilize covariant and contravariant functors for tensor analysis, particularly in the context of vector field applications.
Many Scala developers are familiar with key functional programming principles such as monads, functors, and applicatives. However, these concepts extend beyond Scala and functional programming in general. They originate from areas in mathematics like topology and algebraic topology. In fields such as differential geometry or differential topology, tensors, which utilize covariant and contravariant functors, are extensively employed.
Category theory
Introduction
Category theory is a branch of mathematics that deals with abstract structures and relationships between them. It's a high-level, formal language that's used to unify concepts across various fields of mathematics [ref 1]. Here's a breakdown of its fundamental aspects:
- Categories: At the heart of category theory are categories. A category consists of objects and morphisms (also called arrows or maps) between these objects. Objects can be anything (sets, spaces, groups, etc.), and morphisms are ways of transforming one object into another. Importantly, these transformations must be able to be composed together, and this composition must be associative. Additionally, for each object, there is an identity morphism that acts neutrally in composition.
- Morphisms: These are critical in category theory. A morphism represents a relationship or a function between two objects. It's not just a function in the traditional sense; it's a more generalized concept.
- Functors: These are mappings between categories. A functor respects the structure of categories; it maps objects to objects, morphisms to morphisms, and preserves the composition and identity of morphisms.
- Natural Transformations: These provide a way to transform one functor into another while respecting their action on objects and morphisms.
- Universal Properties: These are properties that define an object in terms of its relationships with other objects, typically describing the 'most efficient' solution to a particular problem.
- Limits and Colimits: These are concepts that generalize constructions like products, coproducts, intersections, and unions.
Category theory is known for its level of abstraction, making it a powerful tool in unifying concepts across different mathematical disciplines. It has found applications in fields such as algebra, topology, and computer science, particularly in the study of functional programming languages. By providing a high-level language for describing and analyzing mathematical structures, category theory helps reveal deep connections between seemingly disparate areas of mathematics.
Covariant functors
A covariant functor F from the category of topological spaces T to some algebraic category C is a function which assigns to each space X an object F(X) in C and to each continuous map f: X → Y a homomorphism F(f): F(X) → F(Y) with \[F(f\circ g)=F(f)\circ F(g)\begin{matrix} & F(id_{X})=id_{Y} \end{matrix}\]
I assume the reader has basic understanding of Functors [ref 2]. Here is short overview:
A category C is composed of object x and morphism f defined as
\[x\in C \Rightarrow F(x)\in D \\ x, y\in C \,\,\, F: x \mapsto y => F(x)\mapsto F(y)\] Let's look at the definition of a functor in Scala with the "preserving" mapping method, map
trait Functor[M[_]] {
def map[U, V](m: M[U])(f: U => V): M[V]
}
Let's define the functor for a vector (or tensor) field. A vector field is defined as a sequence or list of fields (i.e. values or function values).
type VField[U] = List[U]
trait VField_Ftor extends Functor[VField] {
override def map[U, V](vu: VField[U])(f: U => V): VField[V] = vu.map(f)
}
This particular implementation relies on the fact that List is a category with its own functor. The next step is to define the implicit class conversion VField[U] => Functor[VField[U]] so the map method is automatically invoked for each VField instance.
implicit class vField2Functor[U](vu: VField[U]) extends VField_Ftor {
final def map[V](f: U => V): VField[V] = super.map(vu)(f)
}
By default Covariant Functors (which preserve mapping) are known simply as Functors. Let's look at the case of Covector fields.
Contravariant functors
A contravariant functor G is similar to covariant functors. G(f) is a homomorphism from G(Y) to G(X) with \[G(f\circ g)=G(g)\circ G(f)\begin{matrix} & G(id_{X})=id_{Y} \end{matrix}\] A Contravariant functor is a map between two categories that reverses the mapping of morphisms.
\[x, y\in C \,\,\, G: x \mapsto y => G(y)\mapsto G(x)\]trait CoFunctor[M[_]] {
def map[U, V](m: M[U])(f: V => U): M[V] }
The map method of the Cofunctor implements the relation M[V->U] => M[U]->M[V]
Let's implement a co-vector field using a contravariant functor. The definition describes a linear map between a vector V over a field X to the scalar product V*: V => T.
A morphism on the category V* consists of a morphism of V => T or V => _ where V is a vector field and T or _ is a scalar function value.
Let's implement a co-vector field using a contravariant functor. The definition describes a linear map between a vector V over a field X to the scalar product V*: V => T.
A morphism on the category V* consists of a morphism of V => T or V => _ where V is a vector field and T or _ is a scalar function value.
type CoField[V, T] = Function1[V, T]
The co-vector field type, CoField is parameterized on the vector field type V which is a input or function parameter. Therefore the functor has to be contravariant.
The higher kind type M[_] takes a single type as parameter (i.e. M[V]) but a co-vector field requires two types:
- V: Vector field
- T: The scalar function is that the result of the inner product <.>
Fortunately the contravariant functor CoField_Ftor associated with the co-vector needs to be parameterized only with the vector field V. The solution is to pre-defined (or 'fix') the scalar type T using a higher kind projector for the type L[V] => CoField[V, T] T => ({type L[X] = CoField[X,T]})#L
trait CoField_Ftor[T] extends CoFunctor[({type L[X] = CoField[X,T]})#L ] {
override def map[U,V](vu: CoField[U,T])(f: V => U): CoField[V,T] =
(v: V) => vu(f(v))
}
As you can see the morphism over the type V on the category CoField is defined as f: V => U instead of f: U => V. A kind parameterized on the return type (Function1) would require the 'default' (covariant) functor. Once again, we define an implicit class to convert a co-vector field, of type CoField to its functor, CoField2Ftor
implicit class CoField2Ftor [U,T](vu: CoField[U,T]) extends CoField_Ftor {
final def map[V](f: V => U): CoField[V,T] = super.map(vu)(f)
}Monads
A monad is a concept from category theory, a branch of mathematics, which has become particularly important in functional programming. It's a way to represent computations as a series of actions in a specific context, providing a framework for handling side effects, manipulating data, and structuring programs.
A monad is a type of functor, a structure that applies a function to values wrapped in a context.
In functional programming, monads offer a way to deal with side effects (like state, IO,) while keeping the pure functional nature of the code. A monad can be then defined by its 3 methods: unit, map & flatMap [ref 3].
trait Monad[M[_]] {
def unit[T](t: T): M[T]
def map[T, U](m: M[T])(f: T => U): M[U]
def flatMap[T, U](m: M[T])(f: T => M[U]): M[U]
}
Example for List:
- unit(str: String) = List[String](str))
- map(f: (str: String) => str.toUpperCase) = List[String](str.toUpperCase))
- flatMap (f: (str: String) => List[String](str.toUpperCase)) = List[String](str.toUpperCase))
Application to differential geometry
Category theory is applicable to differential geometry and tensor analysis on manifolds [ref 4]
Vector fields
Let's consider a 3 dimension Euclidean space with basis vector {ei} and a vector field V (f1, f2, f3) [Note: we follow Einstein tensor indices convention]
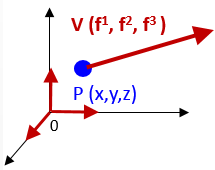
The vector field at the point P(x,y,z) as the tuple (f1(x,y,z), f2(x,y,z), f3(x,y,z)).
The vector over a field of k dimension field can be formally. mathematically defined as
\[f: \boldsymbol{x} \,\, \epsilon \,\,\, \mathbb{R}^{k} \mapsto \mathbb{R} \\ f(\mathbf{x})=\sum_{i=1}^{n}{f^{i}}(\mathbf{x}).\mathbf{e}^{i}\]
Example: \[f(x,y,z) = (2x+z^{3})\boldsymbol{\mathbf{\overrightarrow{i}}} + (xy+e^{-y}-z^{2})\boldsymbol{\mathbf{\overrightarrow{j}}} + \frac{x^{3}}{y}\boldsymbol{\mathbf{\overrightarrow{k}}}\] Now, let's consider the same vector V with a second reference (origin O' and basis vector e'i).

The transformation matrix Sij convert the coordinates value functions fi and f'i. The tuple f =(fi) or more accurately defined as (fi) is the co-vector field for the vector field V
\[S_{ij}: \begin{Vmatrix} f^{1} \\ f^{2} \\ f^{3} \end{Vmatrix} \mapsto \begin{Vmatrix} f'^{1} \\ f'^{2} \\ f'^{3} \end{Vmatrix}\]
The scalar product of the co-vector f' and vector v(f) defined as
\[< f',v> = \sum f'_{i}.f^{i}\]
Given the scalar product we can define the co-vector field f' as a linear map
\[\alpha (v) = < f',v> (1) \] Functors for vector fields
Now we can apply functors to operations on vector fields [ref 5].
Let's consider a field of function values FuncD of two dimension: v(x,y) = f1(x,y).i + f2(x,y).j. The Vector field VFieldD is defined as a list of two function values.
type DVector = Array[Double]
type FuncD = Function1[DVector, Double]
type VFieldD = VField[FuncD]
The vector is computed by assigning a vector field to a specific point (P(1.5, 2.0). The functor is applied to the vector field, vField to generate a new vector field vField2
val f1: FuncD = new FuncD((x: DVector) => x(0)*x(1))
val f2: FuncD = new FuncD((x: DVector) => -2.0*x(1)*x(1))
val vField: VFieldD = List[FuncD](f1, f2)
val value: DVector = Array[Double](1.5, 2.0)
val vField2: VFieldD = vfield.map( _*(4.0))
A co-vector field, coField is computed as the sum of the fields (function values) (lines 1, 2). Next, we compute the product of co-vector field and vector field (scalar field product) (line 3). We simply apply the co-vector Cofield (linear map) to the vector field. Once defined, the morphism _morphism is used to generate a new co-vector field coField2 through the contravariant function CoField2Functor.map (line 6).
Finally, a newProduct is generated by composing the original covariant field coField and the linear map coField2 (line 7).
1
2
3
4
5
6
7 | val coField: CoField[VFieldD, FuncD] = (vf: VFieldD) => vf(0) + vf(1)
val contraFtor: CoField2Functor[VFieldD, FuncD] = coField
val product = coField(vField)
val _morphism: VFieldD => VFieldD = (vf: VFieldD) => vf.map( _*(3.0))
val coField2 = contraFtor.map( _morphism )
val newProduct: FuncD = coField2(coField)
|
Note: This section on the application of functors to vector fields can be extended to tensor fields and smooth manifolds.
Higher kinds in Scala 3
The implementation of functors in Scala 2 relies on the type system been based on class types first (including traits and object classes), along with type projections of the form T#X. Path-dependent types were described as a combination of singleton types and type projections.
({type R[A+] = Either[Int, A]})#R
({type L[B] = Either[B, Int]})#L
Scala 3 modifies the implementation of higher kind projection. It uses the underscore, _, symbol for placeholders in type lambdas [ref 6]. The new, simplified formalism is:
Either[Int, +_]
Either[_, Int]
The new formalism can be used with existing code Scala 2 through a migration library [ref 7].
Thank you for reading this article. For more information ...
References
[3] Monads in Scala
[4] Tensor Analysis on Manifolds- Chap 3 Vector Analysis on Manifolds- R. Bishop, S. Goldberg - Dover publication 1980
[5] Differential Geometric Structures/ Operations on Vector Bundles p20-22 - W. Poor - Dover publications 2007
[7] Kind Projector
---------------------------
Patrick Nicolas has over 25 years of experience in software and data engineering, architecture design and end-to-end deployment and support with extensive knowledge in machine learning.
He has been director of data engineering at Aideo Technologies since 2017 and he is the author of "Scala for Machine Learning" Packt Publishing ISBN 978-1-78712-238-3
He has been director of data engineering at Aideo Technologies since 2017 and he is the author of "Scala for Machine Learning" Packt Publishing ISBN 978-1-78712-238-3



{kind=link}