
Target audience: Advanced
Estimated reading time: 6'
This post explores the back-pressure control in Akka to manage data pipelines.

Overview
Akka is a very reliable and effective library to deploy tasks over multiple cores and over multiple hosts. Fault-tolerance is implemented through a hierarchy of supervising actors, not that different from the Zookeeper framework.
But what about controlling the message flows between actors or clusters of actors? How can we avoid messages backing up in mailboxes for slow, unavailable actors or lengthy computational tasks?
Typesafe has introduced Akka reactive streams and Flow materialization to control TCP back-pressure and manage data flows between actors and cluster of actors. TCP back pressure is a subject for a future post. In the meantime let's design the poor's man back-pressure handler using bounded mail boxes.
But what about controlling the message flows between actors or clusters of actors? How can we avoid messages backing up in mailboxes for slow, unavailable actors or lengthy computational tasks?
Typesafe has introduced Akka reactive streams and Flow materialization to control TCP back-pressure and manage data flows between actors and cluster of actors. TCP back pressure is a subject for a future post. In the meantime let's design the poor's man back-pressure handler using bounded mail boxes.
Note:
For the sake of readability of the implementation of algorithms, all non-essential code such as error checking, comments, exception, validation of class and method arguments, scoping qualifiers or import is omitted.
Workflow
Let's look at a simple computational workflow with the following components:- Workers: These actors process and transform data sets. They start a computation task upon receiving a Compute message that contain the next data set to process. Each worker actor returns the results of the computation (transformed data set) back to the controller using the Completed message.
- Controller is responsible for loading batch of data through a Load message and forward it to the workers in a Compute message. The Controller request the status of the bounded mail box for each worker by sending a GetStatus to the watcher.
- Watcher monitor the state of the workers' mail box and return the current load (as percentage of the mail box is currently used) to the controller with a Status message.

Workers
The worker actor is responsible for processing a slice of data using a function forwarded by the controller. 1
2
3
4
5
6
7
8
9
10
11
12
13 | final class Worker(id: Int) extends Actor {
override def receive = {
// Sent by master/controller to initiate
// the computation with a msg.fct invocation
case msg: Compute => {
val output = msg.fct(msg.xt)
sender ! Completed(id, output, msg.id+1)
}
// last request
case Cleanup => sender ! Done
}
}
|
The worker receives the input to the computation (slice of time series msg.xt and the data transformation msg.fct through the Compute message sent by the controller. Note that the function fct cannot be defined as a closure as the context of the function is unknown to the worker.
The actor return the result output of the computation through the Completed message. Finally all the workers notify the controller that their tasks is completed by responding to the Cleanup message.
The actor return the result output of the computation through the Completed message. Finally all the workers notify the controller that their tasks is completed by responding to the Cleanup message.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19 | type DblSeries = List[Array[Double]]
sealed abstract class Message(val id: Int)
// Sent by worker back to controller
case class Completed(
i: Int,
xt: Array[Double],
nIter: Int) extends Message(i)
// Sent by controller to workers
case class Compute(
i: Int,
xt: DblSeries,
fct: DblSeries => DblSeries) extends Message(i)
case class Cleanup() extends Message(-1)
|
Controller
The worker actor is responsible for processing a slice of data using a function forwarded by the controller. It takes three parameters.- numWorkers: Number of worker actors to create
- watermark: Define the utilization of the worker mail box which trigger a throttle action. If the utilization of the mailbox is below the watermark, the controller throttles up ( increases the pressure) on the actor; If the utilization of the mail box exceeds 1.0 - watermark the controller decreases the pressure on the actor, otherwise the controller does not interfere with the data flow.
- mailboxCapacity:Capacity of the mailboxes for the worker actors (maximum number of messages). It is assumed that all mailboxes have the same capacity.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23 | class Controller(
numWorkers: Int,
watermark: Double,
capacity: Int
) extends Actor {
var id: Int = 0
var batchSize = capacity>>1
// Create a set of worker actors
val workers = List.tabulate(numWorkers)(n =>
context.actorOf(Props(new Worker(n)), name = s"worker$n")
)
val pushTimeout = new FiniteDuration(10, MILLISECONDS)
val msgQueues = workers.map(w =>
(new BoundedMailbox(capacity, pushTimeout))
.create(Some(w), Some(context.system))
)
val watcher = context.actorOf(Props(new Watcher(msgQueues)))
...
}
|
The set of workers are created using the tabulate higher order method. A message queue (mailbox) has to be created for each actor. The mailboxes are bounded in order to avoid buffer overflow. Finally a watch dog actor of type Watcher is created through the Akka context to monitor the mailboxes for the worker. The watcher actor is described in the next sub paragraph.
Let's look at the Controller message loop.
Let's look at the Controller message loop.
1
2
3
4
5
6
7
8
9
10
11 | override def receive = {
// Loads chunk of stream or input data set
case input: Load => load(input.strm)
// processes results from workers
case msg: Completed =>
if(msg.id == -1) kill else process(msg)
// Status on mail boxes utilization sent by the watchdog
case status: Status => throttle(status.load)
}
|
Back-pressure control
The controller performs 3 distinct functions:
- load: Load a variable number of data points and partition them for each worker
- process: Aggregate the results of computation for all the workers
- throttle: Increase or decrease the number of data points loaded at each iteration.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30 | // Load, partition input stream then
// distribute the partitions across the workers
def load(strm: InputStream): Unit =
while( strm.hasNext ) {
val nextBatch = strm.next(batchSize)
partition(nextBatch)
.zip(workers)
.foreach(w => w._2 ! Compute(id, w._1, strm.fct) )
id += 1
}
// Process, aggregate results from all the workers
def process(msg: Completed): Unit = {
.. // aggregation
watcher ! GetStatus
}
// Simple throttle function that increases or decreases the
// size of the next batch of data to be processed by
// workers according to the current load on mail boxes
def throttle(load: Double): Unit = {
if(load < watermark)
batchSize += (batchSize*(load-watermark)).floor.toInt
else if(load > 1.0 - watermark)
batchSize -= (batchSize*(load-1.0 + watermark)).floor.toInt
if( batchSize > (mailboxCapacity>>1) )
batchSize = (mailboxCapacity>>1)
}
|
- load extracts the next batch of data, partitions it then send each partition to a worker actor along with the data transformation fct
- process aggregates the result (Completed) from the transformation on each worker. Then the controller requests a status on the mail box to the watcher
- throttle recompute the size of the next batch, batchSize using the load information provided by the watcher relative to the watermark.
Watcher
The watcher has a simple task: compute the average load of the mailbox of all workers. The computation is done upon reception of the GetStatus message from the controller. 1
2
3
4
5
6
7
8
9
10
11 | class Watcher(
queue: Iterable[MessageQueue]
) extends Actor {
def load = queue.map( _.numberOfMessages)
.sum.toDouble/queue.size
override def receive = {
case GetStatus => sender ! Status(load)
}
}
|
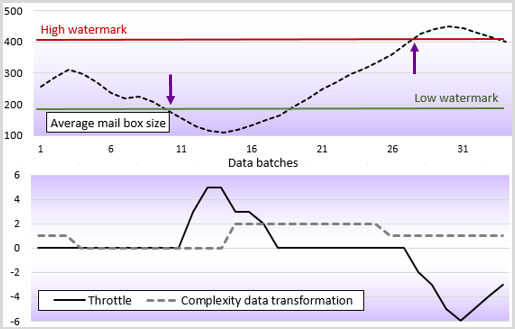
Memory consumption profile
The bottom graph displays the action of the controller (throttling). The Y-axis display the intensity of the throttle from -6 for significant decrease in load (size of batches) to +6 for significant increase in load/pressure on the workers. A throttle index of 0 means that no action is taken by the controller.
The top graph displays the average size of the worker's mailbox, in response of action taken by the controller.
The top graph displays the average size of the worker's mailbox, in response of action taken by the controller.
This implementation of a feedback controller loop is rather crude and mainly described as an introduction to the concept of back pressure control. Production quality implementation relies on:
- TCP-back pressure using reactive streams
- A more sophisticated throttle algorithm to avoid significant adjustment or resonance
- Handling dead letters in case the throttle algorithm fails and the mailbox overflows
References
- Scala for machine learning presentation - P. Nicolas Dec 2014
- Exploring Akka streams for TCP back pressure U. Peter Jan 2015
- Reactive Streams: Handling Data-Flows the Reactive Way Dr R. Kuhn - Typesafe - Aug 2014
- Scala for machine learning Packt Publishing 2014
- github.com/patnicolas


